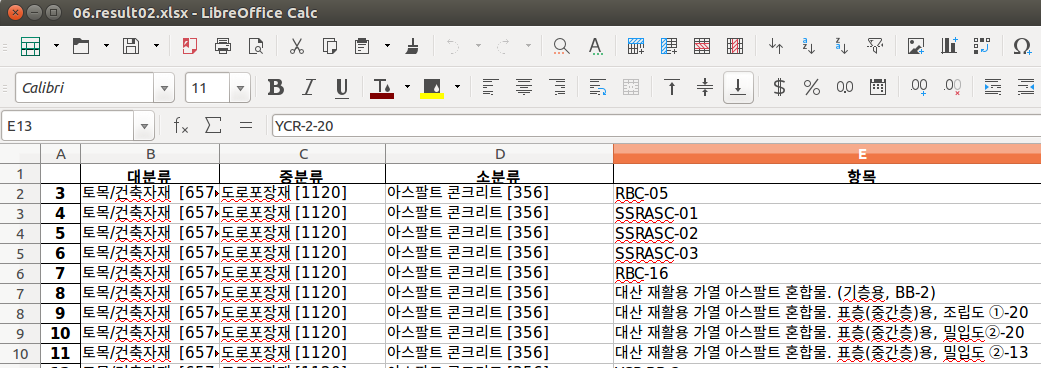
1. 목표와 대상 사이트
1) 목표
- 친환경 건설자재 정보를 수집하여 엑셀에 대/중/소/상세항목 + 연락처 + 제조사 + 홈페이지 + 인증만료기간 을 저장
- 예)
| 대 |
중 |
소 |
연락처 |
제조사 |
홈페이지 |
인증만료기간 |
|
| 토목/건축자재 |
도로포장재 |
아스팔트 콘크리트 |
보령상온재생아스콘(RBC-24) |
063-862-5423 |
(주)청원산업 |
www.cwstar.co.kr |
2017/12/13 |
2) URL
3) 대상 사이트의 특징
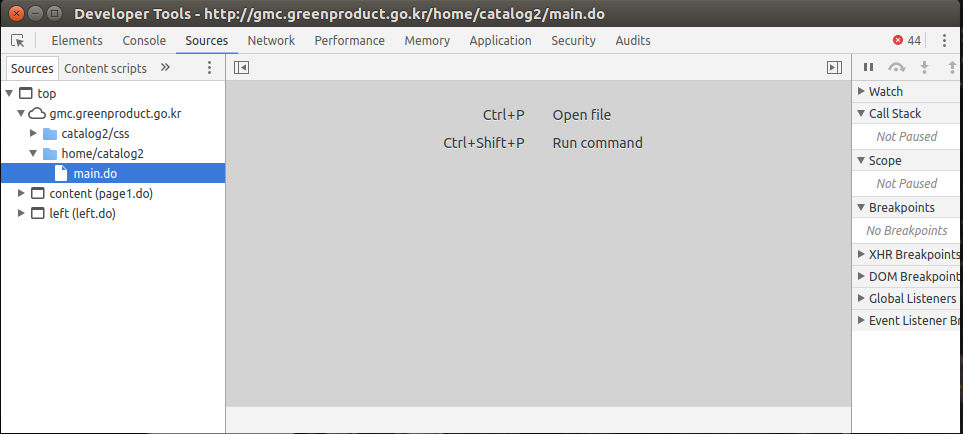
- 크롬개발자도구(
Ctrl + Shift + c) > Source : 프레임 구조 임
- Selenium에서 원래 프레임으로 돌아가는 명령 - driver.switch_to_default_content()
- Selenium에서 프레임간 이동 명령 - driver.switch_to_frame('frame_name')
2. 데이터 얻기 1 - category 정리
import time
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from bs4 import BeautifulSoup
1) Selenium : 대상 사이트 열기
driver = webdriver.Chrome("../crawler/driver/chromedriver")
time.sleep(3)
driver.get('http://gmc.greenproduct.go.kr/home/catalog2/main.do')
driver.switch_to_default_content()
driver.switch_to_frame('left')
html = driver.page_source
2) BeautifulSoup : HTML 태그
1) left 프레임의 메뉴 특징
- table태그의 구성이 중첩됨: table > table > table …
- 각 메뉴는 더블클릭으로 펼칠 수 있다.
- 메뉴를 펼치기 전, 하위 메뉴에 대한 소스 코드가 나타나지 않는다.
2) 대 / 중 / 소 / 상세항목들을 직접 한 단계씩 펼치면서 데이터를 얻는다.
3) 동적 xpath 사용하기
//*[contains( text(), 대분류 항목명 )]
soup = BeautifulSoup(html, 'lxml')
4) 대분류 저장 후 펼치기
# 대분류 저장
layer01_list = []
for layer01name in soup.find_all('td', 'standartTreeRow'):
layer01_list.append( layer01name.get_text() )
layer01_list = layer01_list[1:]
layer01_list[-3:]
['도로시설/자동차용품 [113]', '원부자재/기타 [26]', '섬유/고무/위생/여가 [2]']
# 대분류 펼치기 >> 중분류 + 소분류 + 상세항목 다 나타남 : javaScript : xpath
for item_name in layer01_list:
make_xpath = """//*[contains(text(), '""" + str(item_name) + """')]"""
variable = driver.find_elements_by_xpath(make_xpath)[-1]
print('---> ' + item_name + ' : ' + str(len(driver.find_elements_by_xpath(make_xpath))) )
# 화면에 나타나지 않는 항목 보이게 하기
driver.execute_script("return arguments[0].scrollIntoView();", variable)
# 더블클릭으로 펼치기
ActionChains(driver).double_click(variable).perform()
time.sleep(2)
---> 토목/건축자재 [6577] : 1
---> 기계/설비 [3447] : 1
---> 전기/시험/계측 [2005] : 1
---> 도로시설/자동차용품 [113] : 1
---> 원부자재/기타 [26] : 1
---> 섬유/고무/위생/여가 [2] : 1
5) 중분류 저장 후 펼치기
html = driver.page_source
soup = BeautifulSoup( html, 'lxml')
# 중분류 저장
layer02_list = []
for item in soup.find_all('td', 'standartTreeRow'):
if item.text not in layer01_list:
layer02_list.append( item.text )
layer02_list = layer02_list[ 1: ]
layer02_list[-5:]
['방음벽및방음판 [2]', '용기 및 포장재료 [3]', '동합금 [18]', '기타 [5]', '직물및피혁재료 [2]']
# 중분류 펼치기
time.sleep(1)
count = 0
end_count = len(layer02_list)
for item_name in layer02_list:
make_xpath = """//*[contains(text(), '""" + str(item_name) + """')]"""
variable = driver.find_elements_by_xpath(make_xpath)[0]
count += 1
if count <= 5:
print('---> ' + item_name + ' : ' + str(len(driver.find_elements_by_xpath(make_xpath))) )
# 화면에 나타나지 않는 항목 보이게 하기
driver.execute_script("return arguments[0].scrollIntoView();", variable)
# 더블클릭으로 펼치기
ActionChains(driver).double_click(variable).perform()
time.sleep(2)
---> 도로포장재 [1120] : 1
---> 콘크리트/시멘트 [108] : 1
---> 도로블록 [233] : 1
---> 토목용블록 [203] : 1
---> 벽돌 [267] : 1
6) 소분류 저장 후 펼치기
html = driver.page_source
time.sleep(3)
soup = BeautifulSoup(html, 'lxml')
layer03_list = []
for item in soup.find_all('td', 'standartTreeRow'):
if item.text not in layer01_list + layer02_list:
layer03_list.append(item.text)
layer03_list = layer03_list[ 1: ]
len(layer03_list)
# 소분류 펼치기
time.sleep(3)
count = 0
end_count = len(layer03_list)
for item_name in layer03_list:
make_xpath = """//*[contains(text(), '""" + str(item_name) + """')]"""
variable = driver.find_elements_by_xpath(make_xpath)[0]
count += 1
if count <= 5 or count >= (end_count -5):
print('---> ' + item_name + ' : ' + str(len(driver.find_elements_by_xpath(make_xpath))) )
# 화면에 나타나지 않는 항목 보이게 하기
driver.execute_script("return arguments[0].scrollIntoView();", variable)
time.sleep(1)
# 더블클릭으로 펼치기
ActionChains(driver).double_click(variable).perform()
---> 아스팔트 콘크리트 [356] : 1
---> 포장용채움재 [3] : 1
---> 콘크리트 블록 [374] : 1
---> 경량 혼합재 [2] : 1
---> 보차도용 블록 [194] : 1
---> 재생 주차블럭 [3] : 1
---> 방음벽및방음판(합성수지) [2] : 1
---> 접착제 [3] : 1
---> 주물용 동합금 [18] : 1
---> 고무분말 [5] : 1
---> 장식용 인조피혁 [2] : 1
7) 세부 항목 정리
- 모두 펼쳐진 left 프레임에서 세부 항목을 정리한다. ➔ base_list
- 세부 항목의 개수는 12511
html_display_all = driver.page_source
soup_detail = BeautifulSoup(html_display_all, 'lxml')
time.sleep(3)
base_list = []
for item in soup_detail.find_all('td', 'standartTreeRow'):
base_list.append( item.text )
base_list = base_list[ 1: ]
import numpy as np
layer1 = [ name if name in layer01_list else np.nan for name in base_list ]
layer2 = [ name if name in layer02_list else np.nan for name in base_list ]
layer3 = [ name if name in layer03_list else np.nan for name in base_list ]
layer1[:5], layer2[:5], layer3[:5]
(['토목/건축자재 [6577]', nan, nan, nan, nan],
[nan, '도로포장재 [1120]', nan, nan, nan],
[nan, nan, '아스팔트 콘크리트 [356]', nan, nan])
8) DataFrame 만들기
- NaN 처리 :
pandas.DataFrame.fillna(method='pad', inplace=True)
- (세부)
항목 = 소분류인 항목을 제외하기
result = pd.DataFrame(
{
'대분류' : layer1,
'중분류' : layer2,
'소분류' : layer3,
'항목' : base_list
},
columns= ['대분류', '중분류', '소분류', '항목']
)
result.head()
|
대분류 |
중분류 |
소분류 |
항목 |
| 0 |
토목/건축자재 [6577] |
NaN |
NaN |
토목/건축자재 [6577] |
| 1 |
NaN |
도로포장재 [1120] |
NaN |
도로포장재 [1120] |
| 2 |
NaN |
NaN |
아스팔트 콘크리트 [356] |
아스팔트 콘크리트 [356] |
| 3 |
NaN |
NaN |
NaN |
RBC-05 |
| 4 |
NaN |
NaN |
NaN |
SSRASC-01 |
# NaN 처리
result.fillna(
method='pad',
inplace=True
)
result[358:365]
|
대분류 |
중분류 |
소분류 |
항목 |
| 358 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SA 순환 가열 아스팔트 혼합물(표층용 WC-3) |
| 359 |
토목/건축자재 [6577] |
도로포장재 [1120] |
포장용채움재 [3] |
포장용채움재 [3] |
| 360 |
토목/건축자재 [6577] |
도로포장재 [1120] |
포장용채움재 [3] |
흙콘크리트(BSR10F) |
| 361 |
토목/건축자재 [6577] |
도로포장재 [1120] |
포장용채움재 [3] |
흙콘크리트(BSR100) |
| 362 |
토목/건축자재 [6577] |
도로포장재 [1120] |
포장용채움재 [3] |
지오멘트 |
| 363 |
토목/건축자재 [6577] |
도로포장재 [1120] |
콘크리트 블록 [374] |
콘크리트 블록 [374] |
| 364 |
토목/건축자재 [6577] |
도로포장재 [1120] |
콘크리트 블록 [374] |
내츄럴페이버(투수, SC603W) |
result[ result['항목'].isnull() ]
# 항목 = 소분류
result[ result['항목'] == result['소분류'] ][ :5 ]
|
대분류 |
중분류 |
소분류 |
항목 |
| 2 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
아스팔트 콘크리트 [356] |
| 359 |
토목/건축자재 [6577] |
도로포장재 [1120] |
포장용채움재 [3] |
포장용채움재 [3] |
| 363 |
토목/건축자재 [6577] |
도로포장재 [1120] |
콘크리트 블록 [374] |
콘크리트 블록 [374] |
| 738 |
토목/건축자재 [6577] |
도로포장재 [1120] |
경량 혼합재 [2] |
경량 혼합재 [2] |
| 741 |
토목/건축자재 [6577] |
도로포장재 [1120] |
보차도용 블록 [194] |
보차도용 블록 [194] |
result = result[ result['항목'] != result['소분류'] ]
len(result)
len( result[ result['항목'] == result['소분류'] ] )
result = result[2:]
result.head()
|
대분류 |
중분류 |
소분류 |
항목 |
| 3 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
RBC-05 |
| 4 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SSRASC-01 |
| 5 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SSRASC-02 |
| 6 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SSRASC-03 |
| 7 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
RBC-16 |
3. 데이터 얻기 2 - 함수 처리
1) 목표 - 세부 항목에 따라 원하는 정보를 추출하는 함수들
- 원하는 항목이 보일 때까지 스크롤하고 그 항목의 텍스트를 반환하는 함수( xpath를 통해 )
- 원하는 항목이 보일 때까지 스크롤하고 그 항목을 더블클릭하는 함수
- 원하는 정보를 수집해서 이미 정의된 변수에 저장하는 함수
- 프레임 사이 이동 : 상위 프레임으로 이동하였다가 지정된 프레임으로 이동하는 함수
- 에러 처리 : NaN 입력
2) 스크롤 및 텍스트 반환 함수
def scroll_and_read_text(make_xpath):
variable = driver.find_elements_by_xpath(make_xpath)[0]
time.sleep(0.5)
driver.execute_script("return arguments[0].scrollIntoView();", variable)
return (variable.text)
3) 스크롤 및 더블클릭 함수
def select_item(xpath):
variable = driver.find_elements_by_xpath(make_xpath)[0]
driver.execute_script("return arguments[0].scrollIntoView();", variable)
time.sleep(0.5)
ActionChains(driver).double_click(variable).perform()
time.sleep(2)
4) 수집 정보를 항목 변수에 저장하는 함수
- 임의의 항목 1개 실험
def get_info()
# 임의의 항목 1개 선택하기
select_number = 0
result.iloc[select_number]
대분류 토목/건축자재 [6577]
중분류 도로포장재 [1120]
소분류 아스팔트 콘크리트 [356]
항목 RBC-05
Name: 3, dtype: object
result.iloc[ select_number ]['항목']
# 위 항목에 접근
select_one = result.iloc[ select_number ]['항목']
make_xpath = """//*[contains(text(), '""" + str( select_one ) + """')]"""
variable = driver.find_elements_by_xpath(make_xpath)[0]
driver.execute_script("return arguments[0].scrollIntoView();", variable)
ActionChains(driver).double_click(variable).perform()
# 프레임 변경
driver.switch_to_default_content()
driver.switch_to_frame('content')
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
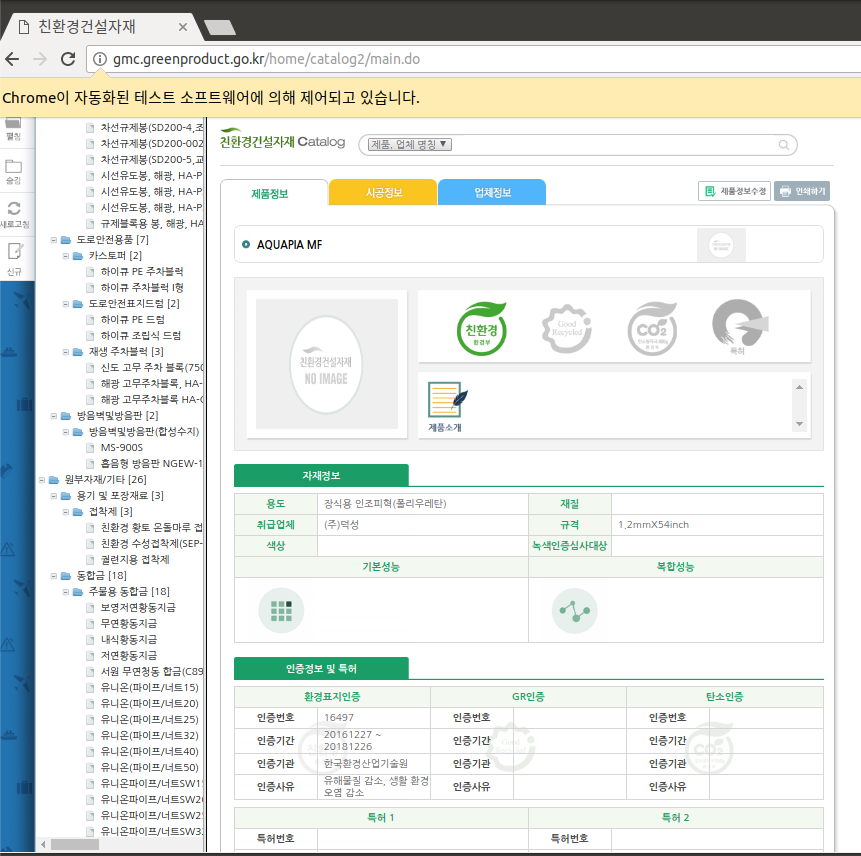
# 제품정보 > 인증정보 및 특허 > 인증기간 > xpath
## //*[@id="tab1c1"]/table[2]/tbody/tr[3]/td[1]
make_xpath = """//*[@id="tab1c1"]/table[2]/tbody/tr[3]/td[1]"""
variable = driver.find_elements_by_xpath(make_xpath)[0]
driver.execute_script("return arguments[0].scrollIntoView();", variable)
variable.text
# 업체정보 탭 클릭
make_xpath = """/html/body/div[1]/ul/li[3]/a"""
driver.find_elements_by_xpath( make_xpath )[0].click()
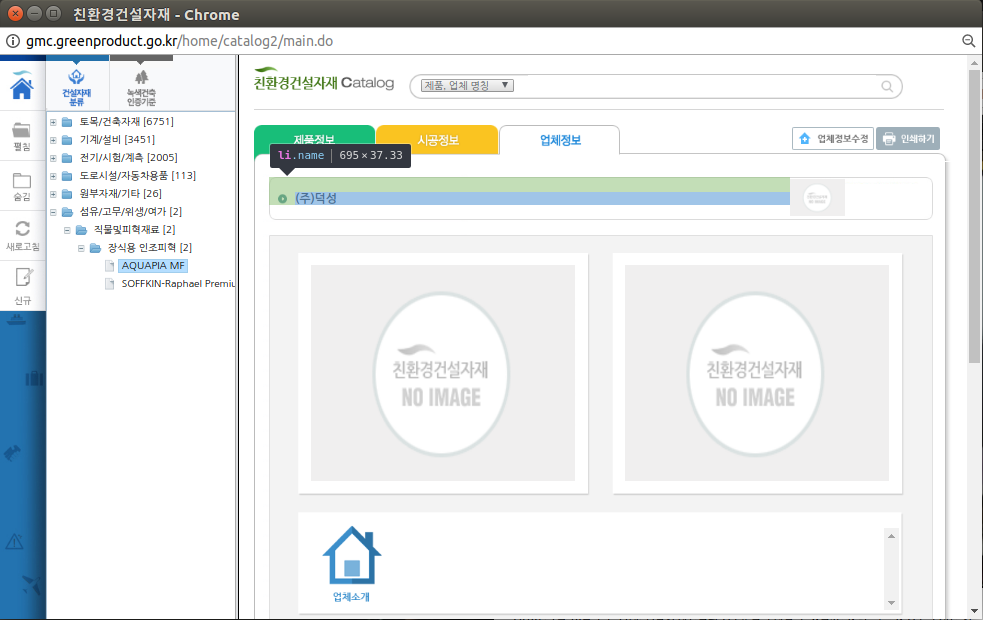
# 업체정보 탭 > 업체 명
# //*[@id="tab1c3"]/div[1]/ul/li[1]
make_xpath = """//*[@id="tab1c3"]/div[1]/ul/li[1]"""
variable = driver.find_elements_by_xpath(make_xpath)[0]
driver.execute_script("return arguments[0].scrollIntoView();", variable)
variable.text
# 업체정보 탭 > 업체정보 란 > 홈페이지
## //*[@id="tab1c3"]/table/tbody/tr[5]/td[2]/a
make_xpath = """//*[@id="tab1c3"]/table/tbody/tr[5]/td[2]/a"""
variable = driver.find_elements_by_xpath( make_xpath )[0]
driver.execute_script("return arguments[0].scrollIntoView();", variable)
variable.text
# 업체정보 탭 > 업체정보 란 > 전화번호
## //*[@id="tab1c3"]/table/tbody/tr[3]/td[2]
make_xpath = """//*[@id="tab1c3"]/table/tbody/tr[3]/td[2]"""
variable = driver.find_elements_by_xpath( make_xpath )[0]
driver.execute_script("return arguments[0].scrollIntoView();", variable)
variable.text
driver.switch_to_default_content()
driver.switch_to_frame('left')
# 함수
def get_info():
# 제품정보 탭 > 인증정보 및 특허 란 > 인증기간
make_xpath = """//*[@id="tab1c1"]/table[2]/tbody/tr[3]/td[1]"""
certification_date.append( scroll_and_read_text( make_xpath ) )
# 업체정보 탭 클릭
make_xpath = """/html/body/div/ul/li[3]/a"""
driver.find_elements_by_xpath( make_xpath )[0].click()
time.sleep(0.5)
# 업체이름
make_xpath = """//*[@id="tab1c3"]/div[1]/ul/li[1]"""
company.append( scroll_and_read_text( make_xpath ) )
# 홈페이지 URL
make_xpath = """//*[@id="tab1c3"]/table/tbody/tr[5]/td[2]/a"""
homepage.append( scroll_and_read_text( make_xpath ) )
# 전화번호
make_xpath = """//*[@id="tab1c3"]/table/tbody/tr[3]/td[2]"""
phone.append( scroll_and_read_text( make_xpath ) )
5) 프레임 이동 함수
- 상위 프레임으로 이동하였다가 지정된 프레임으로 이동함
def switch_frame( frame_name ):
driver.switch_to_default_content()
driver.switch_to_frame( frame_name )
6) 에러 처리
def error_procedure():
company.append( np.nan )
homepage.append( np.nan )
phone.append( np.nan )
certification_date.append( np.nan )
7) 함수 실행
company = []
homepage = []
phone = []
certification_date = []
count = 0
end_count = len(result)
switch_frame('left')
for item in result['항목']:
# 해당 항목에 대한 웹 접근
try:
make_xpath = """//*[contains(text(), '""" + str(item) + """')]"""
select_item(make_xpath)
time.sleep(1)
# 프레임 이동
switch_frame('content')
# 원하는 정보 얻기
get_info()
count += 1
if count % 100 == 0: print(item, ' : ', count, ' / ', end_count )
if count % 500 == 0: break
except:
error_procedure()
print( item, ' : ------------ error --------' )
switch_frame('left')
대산순환가열아스팔트혼합물 (WC-2) : 100 / 12203
주안 재활용가열 아스팔트밀입도 2-13 : 200 / 12203
ASR 표층용 WC-4 : 300 / 12203
내츄럴페이버(투수, SC603W) : ------------ error --------
DS-EM-축조A2 : 400 / 12203
DH-6 : 500 / 12203
4. 데이터 가공
- 에러가 난 부분은 일단 넘어가서 나중에 처리한다
len(company), len(homepage), len(phone), len(certification_date)
company[:5], homepage[:5], phone[:5], certification_date[:5]
(['(주)삼성산업', '(주)삼성산업', '(주)삼성산업', '(주)삼성산업', '(주)선영테크'],
['', '', '', '', ''],
['033-644-3636',
'033-644-3636',
'033-644-3636',
'033-644-3636',
'051-512-9751'],
['20160623 ~ 20180525',
'20160826 ~ 20180825',
'20160826 ~ 20180825',
'20160826 ~ 20180825',
'20161128 ~ 20180730'])
company[0], homepage[0], phone[0], certification_date[0]
('(주)삼성산업', '', '033-644-3636', '20160623 ~ 20180525')
|
대분류 |
중분류 |
소분류 |
항목 |
| 3 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
RBC-05 |
| 4 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SSRASC-01 |
| 5 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SSRASC-02 |
| 6 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SSRASC-03 |
| 7 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
RBC-16 |
company = company[ : 500 ]
homepage = homepage[ : 500 ]
phone = phone[ : 500 ]
certification_date = certification_date[ : 500 ]
result = result[ : 500 ]
len(company), len(homepage), len(phone), len(certification_date)
result.is_copy = False
result['제조사'] = company
result['홈페이지'] = homepage
result['연락처'] = phone
result['인증기간'] = certification_date
result.head()
|
대분류 |
중분류 |
소분류 |
항목 |
제조사 |
홈페이지 |
연락처 |
인증기간 |
| 3 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
RBC-05 |
(주)삼성산업 |
|
033-644-3636 |
20160623 ~ 20180525 |
| 4 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SSRASC-01 |
(주)삼성산업 |
|
033-644-3636 |
20160826 ~ 20180825 |
| 5 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SSRASC-02 |
(주)삼성산업 |
|
033-644-3636 |
20160826 ~ 20180825 |
| 6 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SSRASC-03 |
(주)삼성산업 |
|
033-644-3636 |
20160826 ~ 20180825 |
| 7 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
RBC-16 |
(주)선영테크 |
|
051-512-9751 |
20161128 ~ 20180730 |
(1) 에러 처리
result[ result['제조사'].isnull() ]
|
대분류 |
중분류 |
소분류 |
항목 |
제조사 |
홈페이지 |
연락처 |
인증기간 |
| 365 |
토목/건축자재 [6577] |
도로포장재 [1120] |
콘크리트 블록 [374] |
잔디블록(ASIA-GRASS-10) |
NaN |
http;//www.asiasanup.co.kr |
044-857-7811 |
NaN |
# def get_info():
# # 제품정보 탭 > 인증정보 및 특허 란 > 인증기간
# make_xpath = """//*[@id="tab1c1"]/table[2]/tbody/tr[3]/td[1]"""
# certification_date.append( scroll_and_read_text( make_xpath ) )
#
# # 업체정보 탭 클릭
# make_xpath = """/html/body/div/ul/li[3]/a"""
# driver.find_elements_by_xpath( make_xpath )[0].click()
# time.sleep(0.5)
#
# # 업체이름
# make_xpath = """//*[@id="tab1c3"]/div[1]/ul/li[1]"""
# company.append( scroll_and_read_text( make_xpath ) )
#
# # 홈페이지 URL
# make_xpath = """//*[@id="tab1c3"]/table/tbody/tr[5]/td[2]"""
# homepage.append( scroll_and_read_text( make_xpath ) )
#
# # 전화번호
# make_xpath = """//*[@id="tab1c3"]/table/tbody/tr[3]/td[2]"""
# phone.append( scroll_and_read_text( make_xpath ) )
def replace_info(n):
# 제품정보 탭 > 인증정보 및 특허 란 > 인증기간
make_xpath = """//*[@id="tab1c1"]/table[2]/tbody/tr[3]/td[1]"""
result.loc[n, '인증기간'] = scroll_and_read_text(make_xpath)
# 업체정보 탭 클릭
make_xpath = """/html/body/div/ul/li[3]/a"""
variable = driver.find_elements_by_xpath( make_xpath )[0].click()
time.sleep(0.5)
# 업체이름
make_xpath = """//*[@id="tab1c3"]/div[1]/ul/li[1]"""
time.sleep(0.5)
result.loc[n, '제조사'] = scroll_and_read_text(make_xpath)
time.sleep(0.5)
# 홈페이지 URL
make_xpath = """//*[@id="tab1c3"]/table/tbody/tr[5]/td[2]/a"""
time.sleep(0.5)
result.loc[n, '홈페이지'] = scroll_and_read_text(make_xpath)
time.sleep(0.5)
# 전화번호
make_xpath = """//*[@id="tab1c3"]/table/tbody/tr[3]/td[2]"""
time.sleep(0.5)
result.loc[n, '연락처'] = scroll_and_read_text(make_xpath)
time.sleep(0.5)
for n in result[ result['제조사'].isnull() ].index:
try:
make_xpath = """//*[contains(text(), '""" + str(result['항목'][n]) + """')]"""
print( str(result['항목'][n]) + ' : ---- entrance ----' )
select_item(make_xpath)
print( str(result['항목'][n]) + ' : --- click item ---' )
time.sleep(0.5)
switch_frame('content')
print( str(result['항목'][n]) + ' : --- change frame ---')
replace_info(n)
print( str(result['항목'][n]) + ' : --- success ---' )
except:
print( str(result['항목'][n]) + ' : --- error ----' )
switch_frame('left')
time.sleep(1)
for n in [365]:
try:
make_xpath = """//*[contains(text(), '""" + str(result['항목'][n]) + """')]"""
print( str(result['항목'][n]) + ' : ---- entrance ----' )
select_item(make_xpath)
print( str(result['항목'][n]) + ' : --- click item ---' )
time.sleep(0.5)
switch_frame('content')
print( str(result['항목'][n]) + ' : --- change frame ---')
replace_info(n)
print( str(result['항목'][n]) + ' : --- success ---' )
except:
print( str(result['항목'][n]) + ' : --- error ----' )
switch_frame('left')
time.sleep(1)
잔디블록(ASIA-GRASS-10) : ---- entrance ----
잔디블록(ASIA-GRASS-10) : --- click item ---
잔디블록(ASIA-GRASS-10) : --- change frame ---
잔디블록(ASIA-GRASS-10) : --- success ---
# 확인
result[ result['항목'] == '잔디블록(ASIA-GRASS-10)' ]
|
대분류 |
중분류 |
소분류 |
항목 |
제조사 |
홈페이지 |
연락처 |
인증기간 |
| 365 |
토목/건축자재 [6577] |
도로포장재 [1120] |
콘크리트 블록 [374] |
잔디블록(ASIA-GRASS-10) |
(주)아세아산업 |
http;//www.asiasanup.co.kr |
044-857-7811 |
20161005 ~ 20181004 |
2) 엑셀 저장
(1) openpyxl 모듈
openpyxl 공식문서
➜ pip install openpyxl
Collecting openpyxl
Downloading openpyxl-2.4.10.tar.gz (158kB)
100% |████████████████████████████████| 163kB 1.0MB/s
Collecting jdcal (from openpyxl)
Downloading jdcal-1.3.tar.gz
Collecting et_xmlfile (from openpyxl)
Downloading et_xmlfile-1.0.1.tar.gz
Installing collected packages: jdcal, et-xmlfile, openpyxl
Running setup.py install for jdcal ... done
Running setup.py install for et-xmlfile ... done
Running setup.py install for openpyxl ... done
Successfully installed et-xmlfile-1.0.1 jdcal-1.3 openpyxl-2.4.10
(2) xlsxwriter 모듈
xlsxwriter 공식문서
➜ pip install XlsxWriter
Collecting XlsxWriter
Downloading XlsxWriter-1.0.2-py2.py3-none-any.whl (139kB)
100% |████████████████████████████████| 143kB 1.2MB/s
Installing collected packages: XlsxWriter
Successfully installed XlsxWriter-1.0.2
(3) 엑셀저장
result.to_excel('./data_ouput/06.result.xlsx', sheet_name='Sheet1')
3) 데이터 다듬기
import pandas as pd
import re
import numpy as np
df = pd.read_excel('./data_ouput/06.result.xlsx')
df.head(3)
|
대분류 |
중분류 |
소분류 |
항목 |
제조사 |
홈페이지 |
연락처 |
인증기간 |
| 3 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
RBC-05 |
(주)삼성산업 |
NaN |
033-644-3636 |
20160623 ~ 20180525 |
| 4 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SSRASC-01 |
(주)삼성산업 |
NaN |
033-644-3636 |
20160826 ~ 20180825 |
| 5 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SSRASC-02 |
(주)삼성산업 |
NaN |
033-644-3636 |
20160826 ~ 20180825 |
# 인증만료기간
tmp_list = []
for tmp in df['인증기간']:
try:
tmp_list.append( re.split('~', tmp)[-1] )
except:
tmp_list.append(tmp)
df['인증만료기간'] = tmp_list
df.head(3)
|
대분류 |
중분류 |
소분류 |
항목 |
제조사 |
홈페이지 |
연락처 |
인증기간 |
인증만료기간 |
| 3 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
RBC-05 |
(주)삼성산업 |
NaN |
033-644-3636 |
20160623 ~ 20180525 |
20180525 |
| 4 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SSRASC-01 |
(주)삼성산업 |
NaN |
033-644-3636 |
20160826 ~ 20180825 |
20180825 |
| 5 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SSRASC-02 |
(주)삼성산업 |
NaN |
033-644-3636 |
20160826 ~ 20180825 |
20180825 |
[' 20180525', ' 20180825', ' 20180825', ' 20180825', ' 20180730']
tone= tmp_list[0]
year_month_day = tone.replace(' ', '').replace('-', '')
tyear = year_month_day[:4]
tmonth = year_month_day[4:6]
tday = year_month_day[6:8]
tone, tyear, tmonth, tday, tyear + '/' + tmonth + '/' + tday
(' 20180525', '2018', '05', '25', '2018/05/25')
t_list = []
for tmp in tmp_list:
try:
# 빈칸과 '-' 기호 없애기
tmp2 = tmp.replace(' ', '').replace('-', '')
# 년
tmp_year = tmp2[:4]
# 월
tmp_month = tmp2[4:6]
# 일
tmp_day = tmp2[6:8]
# 년/월/일
year_month_day = tmp_year + '/' + tmp_month + '/' + tmp_day
t_list.append(year_month_day)
except:
t_list.append(np.nan)
t_list[0]
df['인증만료기간'] = t_list
df.head(3)
|
대분류 |
중분류 |
소분류 |
항목 |
제조사 |
홈페이지 |
연락처 |
인증기간 |
인증만료기간 |
| 3 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
RBC-05 |
(주)삼성산업 |
NaN |
033-644-3636 |
20160623 ~ 20180525 |
2018/05/25 |
| 4 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SSRASC-01 |
(주)삼성산업 |
NaN |
033-644-3636 |
20160826 ~ 20180825 |
2018/08/25 |
| 5 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SSRASC-02 |
(주)삼성산업 |
NaN |
033-644-3636 |
20160826 ~ 20180825 |
2018/08/25 |
|
대분류 |
중분류 |
소분류 |
항목 |
제조사 |
홈페이지 |
연락처 |
인증만료기간 |
| 3 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
RBC-05 |
(주)삼성산업 |
NaN |
033-644-3636 |
2018/05/25 |
| 4 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SSRASC-01 |
(주)삼성산업 |
NaN |
033-644-3636 |
2018/08/25 |
df = pd.DataFrame(
df,
columns=['대분류', '중분류', '소분류', '항목', '제조사', '인증만료기간', '연락처', '홈페이지']
)
df.head(2)
|
대분류 |
중분류 |
소분류 |
항목 |
제조사 |
인증만료기간 |
연락처 |
홈페이지 |
| 3 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
RBC-05 |
(주)삼성산업 |
2018/05/25 |
033-644-3636 |
NaN |
| 4 |
토목/건축자재 [6577] |
도로포장재 [1120] |
아스팔트 콘크리트 [356] |
SSRASC-01 |
(주)삼성산업 |
2018/08/25 |
033-644-3636 |
NaN |
writer = pd.ExcelWriter('./data_ouput/06.result02.xlsx', engine='xlsxwriter')
df.to_excel(writer, sheet_name='Sheet1')
workbook = writer.book
worksheet = writer.sheets['Sheet1']
worksheet.set_column('A:A', 4)
worksheet.set_column('B:B', 15)
worksheet.set_column('C:C', 18)
worksheet.set_column('D:D', 25)
worksheet.set_column('E:E', 55)
worksheet.set_column('F:F', 18)
worksheet.set_column('G:G', 18)
worksheet.set_column('H:H', 18)
worksheet.set_column('I:I', 18)
writer.save()