데이터 사이언스 03 웹자료 가져오기(1)-BeautifulSoup
1. 참조
2. 설치
1) BeautifulSoup + lxml
- install BeautifulSoup:
➯ pip install beautifulsoup4 - install HTML parser :
➯ pip install lxml
2) requests
- requests 공식문서
- 나만의 웹크롤러 만들기 with Requests/BeautifulSoup
- urllib.request.urlopen 모듈 대신 requests.get이 직관적으로 사용하기 쉬움
- requests.get(URL)
- requests.compat.urljoin( BASE_address, relative_URL )
3. 구글 크롬 개발자 도구
1) XPATH
XPath(XML Path Language)는 W3C의 표준으로 확장 생성 언어 문서의 구조를 통해 경로 위에 지정한 구문을 사용하여 항목을 배치하고 처리하는 방법을 기술하는 언어이다. XML 표현보다 더 쉽고 약어로 되어 있으며, XSL 변환(XSLT)과 XML 지시자 언어(XPointer)에 쓰이는 언어이다. XPath는 XML 문서의 노드를 정의하기 위하여 경로식을 사용하며, 수학 함수와 기타 확장 가능한 표현들이 있다.
4. 시카고 샌드위치 맛집 소개 페이지 만들기
1) Web page 분석
-
구글링 : 50 best sandwiches in chicago
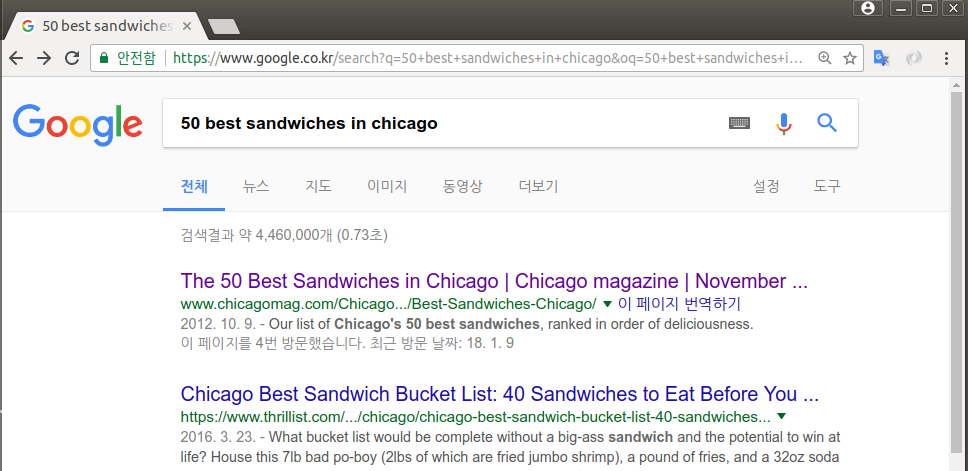
-
최종 목표
| 1 | Old Oak Tap | BLT | 10. | 2109 W. Chicago Ave. | http://www.chicagomag.com/Chicago-Magazine/ |
2) BASE 페이지
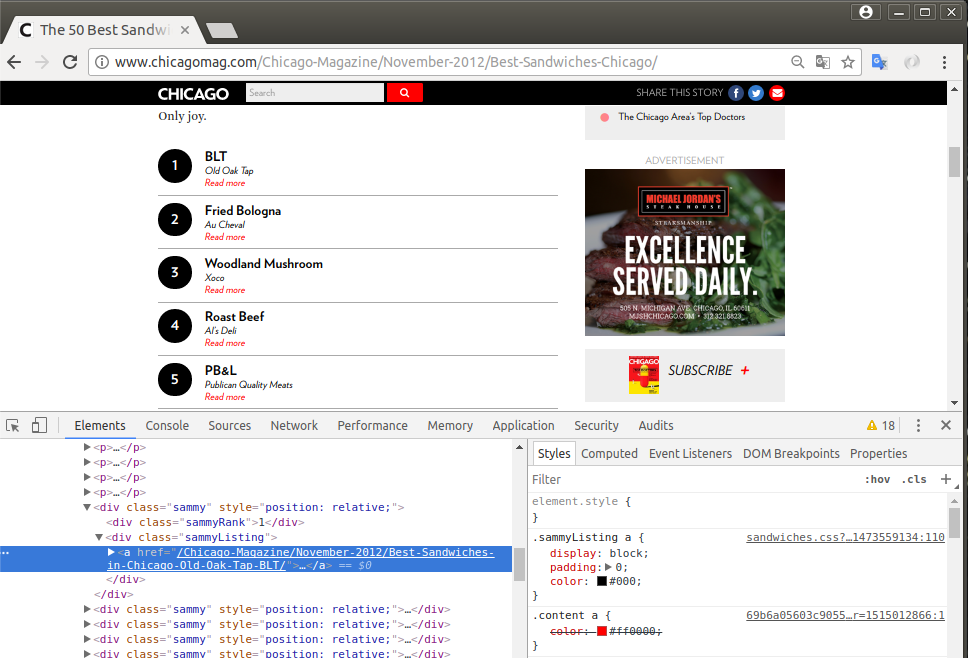
# parser.py
import requests
from bs4 import BeautifulSoup
# HTTP GET Request
response = requests.get('http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-Chicago/')
# HTML 소스 가져오기
html = response.text
# BeautifulSoup으로 html소스를 python객체로 변환하기
# 첫 인자는 html소스코드, 두 번째 인자는 어떤 parser를 이용할지 명시.
# 여기에는 lxml(Python 내장 html.parser를 쓸 수 있다)를 이용했다.
soup = BeautifulSoup(html, 'lxml')
- 각각의 소개 페이지 : 50개의 샌드위치 가게를 소개하는 base 페이지에 대한 태그 분석
len( soup.find_all('div', 'sammy') )
50
soup.find_all('div', 'sammy')[0]
<div class="sammy" style="position: relative;">
<div class="sammyRank">1</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/"><b>BLT</b><br/>
Old Oak Tap<br/>
<em>Read more</em> </a></div>
</div>
tmp1 = soup.find_all('div', 'sammy')[0]
# 가게 순위
tmp1.findChildren()[0]
<div class="sammyRank">1</div>
tmp1.findChildren()[0].get_text()
'1'
# 메뉴와 가게 이름
tmp1.findChildren()[1]
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/"><b>BLT</b><br/>
Old Oak Tap<br/>
<em>Read more</em> </a></div>
tmp1.findChildren()[1].get_text().replace('\r', '').split('\n')[:-1]
['BLT', 'Old Oak Tap']
# 잡지내 상대 URL
tmp1.findChildren()[1].a.get('href')
'/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/'
# 절대 주소
base_address = 'http://www.chicagomag.com'
abs_address = requests.compat.urljoin( base_address, tmp1.findChildren()[1].a.get('href') )
abs_address
'http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/'
- **50개 가게 리스트 정리 **
rank = []
main_menu = []
cafe_name = []
url_add = []
list_soup = soup.find_all('div', 'sammy')
for item in list_soup:
child = item.findChildren()
#순위
rank.append(child[0].get_text())
#메뉴와 가게이름
tmp = child[1].get_text().replace('\r', '').split('\n')[:-1]
#메인 메뉴
main_menu.append( tmp[0] )
#가게 이름
cafe_name.append( tmp[1] )
# URL
base_address = 'http://www.chicagomag.com'
abs_address = requests.compat.urljoin( base_address, child[1].a.get('href') )
url_add.append( abs_address )
# for-Loop 결과 확인
rank[:5], main_menu[:5], cafe_name[:5], url_add[:10]
(['1', '2', '3', '4', '5'],
['BLT', 'Fried Bologna', 'Woodland Mushroom', 'Roast Beef', 'PB&L'],
['Old Oak Tap', 'Au Cheval', 'Xoco', 'Al’s Deli', 'Publican Quality Meats'],
['http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/',
'http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Au-Cheval-Fried-Bologna/',
'http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Xoco-Woodland-Mushroom/',
'http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Als-Deli-Roast-Beef/',
'http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Publican-Quality-Meats-PB-L/',
'http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Hendrickx-Belgian-Bread-Crafter-Belgian-Chicken-Curry-Salad/',
'http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Acadia-Lobster-Roll/',
'http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Birchwood-Kitchen-Smoked-Salmon-Salad/',
'http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Cemitas-Puebla-Atomica-Cemitas/',
'http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Nana-Grilled-Laughing-Bird-Shrimp-and-Fried-Oyster-Po-Boy/'])
# 무결성 체크
len(rank), len(main_menu), len(cafe_name), len(url_add)
(50, 50, 50, 50)
- pandas.DataFrame에 저장
import pandas as pd
data = {'Rank':rank, "Menu":main_menu, "Cafe": cafe_name, "URL":url_add}
df = pd.DataFrame(
data,
columns=['Rank', 'Cafe', 'Menu', 'URL']
)
df.head()
| Rank | Cafe | Menu | URL | |
|---|---|---|---|---|
| 0 | 1 | Old Oak Tap | BLT | http://www.chicagomag.com/Chicago-Magazine/Nov... |
| 1 | 2 | Au Cheval | Fried Bologna | http://www.chicagomag.com/Chicago-Magazine/Nov... |
| 2 | 3 | Xoco | Woodland Mushroom | http://www.chicagomag.com/Chicago-Magazine/Nov... |
| 3 | 4 | Al’s Deli | Roast Beef | http://www.chicagomag.com/Chicago-Magazine/Nov... |
| 4 | 5 | Publican Quality Meats | PB&L | http://www.chicagomag.com/Chicago-Magazine/Nov... |
df.to_csv('./data_ouput/03.best_sandwiches_list_chicago.csv', sep=',', encoding='utf-8')
3) 하위 페이지 접근
-
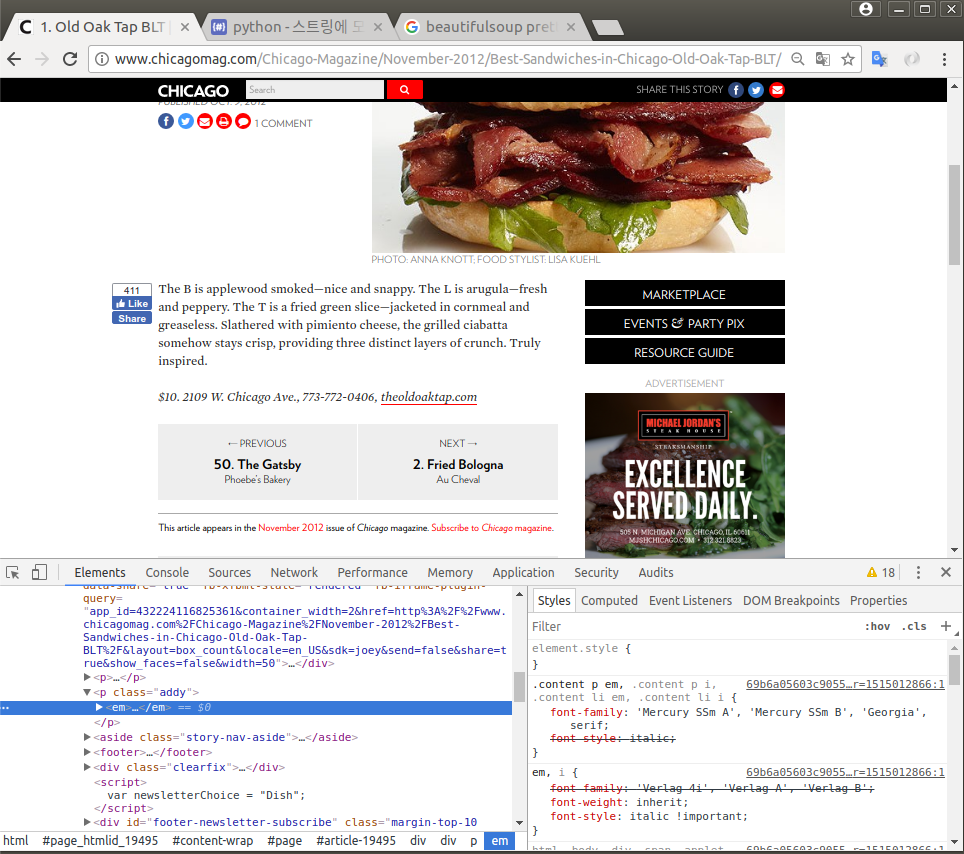
샘플링: 첫번째 가게 : BLT http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/
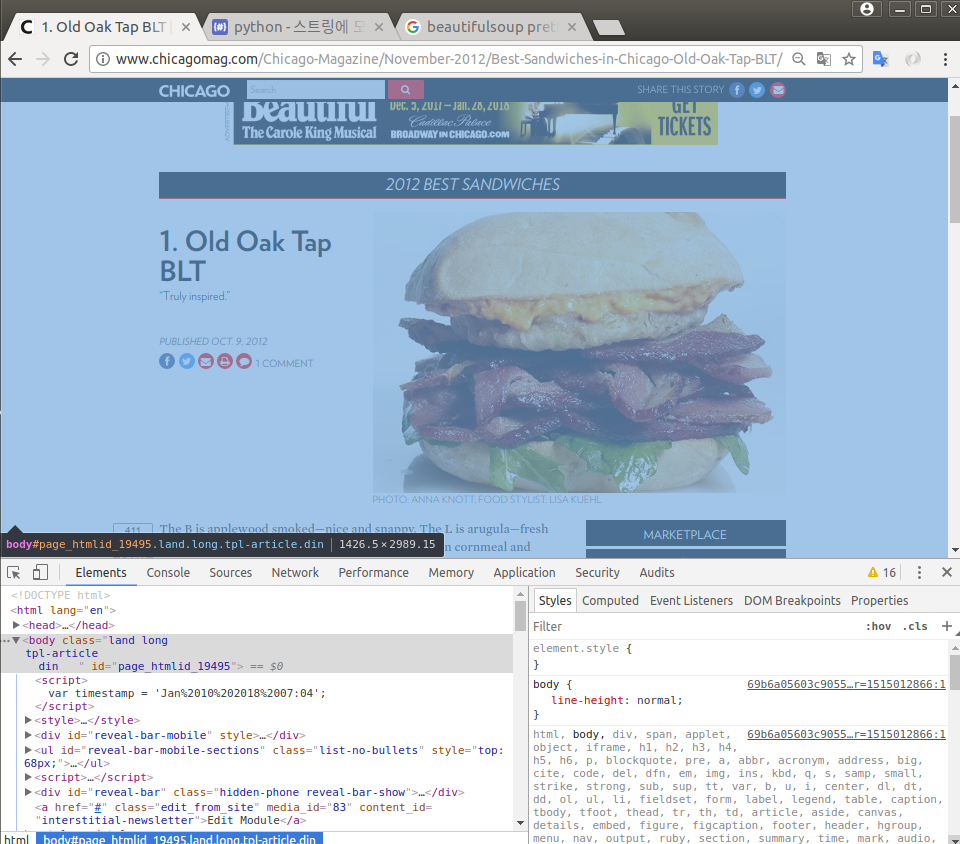
-
가격, 주소, 전화, 홈페이지 주소
df['URL'][0]
'http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/'
response = requests.get( df['URL'][0] )
html = response.text
soup_tmp = BeautifulSoup( html, 'lxml' )
tmp = soup_tmp.find('p', 'addy').get_text().strip()
tmp
'$10. 2109 W. Chicago Ave., 773-772-0406, theoldoaktap.com'
-
가격과 주소 부분 - <pre>$으로 시작해서 첫번째 콤마(,)까지</pre>
-
가격과 주소 구분 - <pre>$으로 시작해서 숫자가 나오다가 점(.) 다음에 숫자가 있거나 혹은 공백까지 </pre>
tmp_price = tmp[ tmp.find('$') : tmp.find(' ') ]
tmp_price
'$10.'
tmp_address = tmp[ tmp.find(' ') : tmp.find(',') ]
tmp_address
' 2109 W. Chicago Ave.'
- 5개 샘플링
price = []
address = []
for n in range(5):
response = requests.get( df['URL'][n] )
html = response.text
soup_tmp = BeautifulSoup( html, 'lxml' )
tmp = soup_tmp.find('p', 'addy').get_text().strip()
tmp_price = tmp[ tmp.find('$') : tmp.find(' ')-1 ]
tmp_address = tmp[ tmp.find(' ') : tmp.find(',') ]
print( tmp_price, "+", tmp_address )
$10 + 2109 W. Chicago Ave.
$9 + 800 W. Randolph St.
$9.50 + 445 N. Clark St.
$9.40 + 914 Noyes St.
$10 + 825 W. Fulton Mkt.
- 전체 for-Loop
df.index
RangeIndex(start=0, stop=50, step=1)
price = []
address = []
for n in df.index:
response = requests.get( df['URL'][n] )
html = response.text
soup = BeautifulSoup( html, 'lxml' )
item = soup.find('p', 'addy').get_text().strip()
item_price = item[ item.find('$') : item.find(' ') - 1 ]
item_address = item[ item.find(' ') : item.find(',') ]
price.append(item_price)
address.append(item_address)
len(price), len(address), len(df)
(50, 50, 50)
df['Price'] = price
df['Address'] = address
df.tail()
| Rank | Cafe | Menu | URL | Price | Address | |
|---|---|---|---|---|---|---|
| 45 | 46 | Chickpea | Kufta | http://www.chicagomag.com/Chicago-Magazine/Nov... | $8 | 2018 W. Chicago Ave. |
| 46 | 47 | The Goddess and Grocer | Debbie’s Egg Salad | http://www.chicagomag.com/Chicago-Magazine/Nov... | $6.50 | 25 E. Delaware Pl. |
| 47 | 48 | Zenwich | Beef Curry | http://www.chicagomag.com/Chicago-Magazine/Nov... | $7.50 | 416 N. York St. |
| 48 | 49 | Toni Patisserie | Le Végétarien | http://www.chicagomag.com/Chicago-Magazine/Nov... | $8.75 | 65 E. Washington St. |
| 49 | 50 | Phoebe’s Bakery | The Gatsby | http://www.chicagomag.com/Chicago-Magazine/Nov... | $6.85 | 3351 N. Broadway |
df = df.loc[:, ['Rank', 'Cafe', 'Menu', 'Price', 'Address', 'URL' ] ]
df.tail()
| Rank | Cafe | Menu | Price | Address | URL | |
|---|---|---|---|---|---|---|
| 45 | 46 | Chickpea | Kufta | $8 | 2018 W. Chicago Ave. | http://www.chicagomag.com/Chicago-Magazine/Nov... |
| 46 | 47 | The Goddess and Grocer | Debbie’s Egg Salad | $6.50 | 25 E. Delaware Pl. | http://www.chicagomag.com/Chicago-Magazine/Nov... |
| 47 | 48 | Zenwich | Beef Curry | $7.50 | 416 N. York St. | http://www.chicagomag.com/Chicago-Magazine/Nov... |
| 48 | 49 | Toni Patisserie | Le Végétarien | $8.75 | 65 E. Washington St. | http://www.chicagomag.com/Chicago-Magazine/Nov... |
| 49 | 50 | Phoebe’s Bakery | The Gatsby | $6.85 | 3351 N. Broadway | http://www.chicagomag.com/Chicago-Magazine/Nov... |
df.to_csv('./data_ouput/03.best_sandwiches_list_chicago2.csv', sep=',', encoding='UTF-8' )
4) 지도 시각화
import folium
import pandas as pd
import googlemaps
import numpy as np
gmaps = googlemaps.Client(key="AIzaSyC58AWrye6Z-2vAdoEVv_Xsf6sk6Vsg_90")
tmp = df['Address'][1] + ', ' + 'Chicago'
tmp
' 800 W. Randolph St., Chicago'
tmpMap = gmaps.geocode(tmp)
tmpMap
[{'address_components': [{'long_name': '800',
'short_name': '800',
'types': ['street_number']},
{'long_name': 'West Randolph Street',
'short_name': 'W Randolph St',
'types': ['route']},
{'long_name': 'West Loop',
'short_name': 'West Loop',
'types': ['neighborhood', 'political']},
{'long_name': 'Chicago',
'short_name': 'Chicago',
'types': ['locality', 'political']},
{'long_name': 'Cook County',
'short_name': 'Cook County',
'types': ['administrative_area_level_2', 'political']},
{'long_name': 'Illinois',
'short_name': 'IL',
'types': ['administrative_area_level_1', 'political']},
{'long_name': 'United States',
'short_name': 'US',
'types': ['country', 'political']},
{'long_name': '60607', 'short_name': '60607', 'types': ['postal_code']},
{'long_name': '2308',
'short_name': '2308',
'types': ['postal_code_suffix']}],
'formatted_address': '800 W Randolph St, Chicago, IL 60607, USA',
'geometry': {'location': {'lat': 41.8846582, 'lng': -87.6476668},
'location_type': 'ROOFTOP',
'viewport': {'northeast': {'lat': 41.88600718029149,
'lng': -87.64631781970849},
'southwest': {'lat': 41.88330921970849, 'lng': -87.6490157802915}}},
'place_id': 'ChIJNQXlSMUsDogRPCtvEAVtglU',
'types': ['street_address']}]
tmp_loc = tmpMap[0].get('geometry')
tmp_loc
{'location': {'lat': 41.8846582, 'lng': -87.6476668},
'location_type': 'ROOFTOP',
'viewport': {'northeast': {'lat': 41.88600718029149,
'lng': -87.64631781970849},
'southwest': {'lat': 41.88330921970849, 'lng': -87.6490157802915}}}
tmp_loc['location']['lat'], tmp_loc['location']['lng']
(41.8846582, -87.6476668)
lat = []
lng = []
for n in df.index:
if df['Address'][n] == 'Multiple locations':
lat.append(np.nan)
lng.append(np.nan)
elif df['Address'][n] != 'Multiple locations':
tmp = df['Address'][n] + ', ' + 'Chicago'
tmp_map = gmaps.geocode(tmp)
tmp_loc = tmp_map[0].get('geometry')
lat.append(tmp_loc['location']['lat'])
lng.append(tmp_loc['location']['lng'])
len(lat), len(lng)
(50, 50)
df['lat'] = lat
df['lng'] = lng
df.head()
| Rank | Cafe | Menu | Price | Address | URL | lat | lng | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Old Oak Tap | BLT | $10 | 2109 W. Chicago Ave. | http://www.chicagomag.com/Chicago-Magazine/Nov... | 41.895605 | -87.679961 |
| 1 | 2 | Au Cheval | Fried Bologna | $9 | 800 W. Randolph St. | http://www.chicagomag.com/Chicago-Magazine/Nov... | 41.884658 | -87.647667 |
| 2 | 3 | Xoco | Woodland Mushroom | $9.50 | 445 N. Clark St. | http://www.chicagomag.com/Chicago-Magazine/Nov... | 41.890570 | -87.630795 |
| 3 | 4 | Al’s Deli | Roast Beef | $9.40 | 914 Noyes St. | http://www.chicagomag.com/Chicago-Magazine/Nov... | 42.058322 | -87.683748 |
| 4 | 5 | Publican Quality Meats | PB&L | $10 | 825 W. Fulton Mkt. | http://www.chicagomag.com/Chicago-Magazine/Nov... | 41.886596 | -87.648557 |
mapping = folium.Map(
location=[ df['lat'].mean(), df['lng'].mean() ],
zoom_start=11
)
for n in df.index:
if df['Address'][n] != 'Multiple locations':
folium.Marker(
[ df['lat'][n], df['lng'][n] ],
popup=df['Cafe'][n]
).add_to(mapping)
mapping
5. 서울시 구별 맥도널드 매장 수
1) URL 창
- 매장찾기 : http://www.mcdonalds.co.kr/www/kor/findus/district.do
서울특별시 강남구검색
http://www.mcdonalds.co.kr/www/kor/findus/district.do?pageIndex=2&sSearch_yn=Y&skey=2&skey1=&skey2=&skeyword=서울특별시%20강남구&skey4=&skey5=&skeyword2=&sflag1=&sflag2=&sflag3=&sflag4=&sflag5=&sflag6=&sflag=N
➞
http://www.mcdonalds.co.kr/www/kor/findus/district.do?pageIndex=2&sSearch_yn=Y&skey=2&skey1=&skey2=&skeyword=%EC%84%9C%EC%9A%B8%ED%8A%B9%EB%B3%84%EC%8B%9C%20%EA%B0%95%EB%82%A8%EA%B5%AC&skey4=&skey5=&skeyword2=&sflag1=&sflag2=&sflag3=&sflag4=&sflag5=&sflag6=&sflag=N
- http://www.mcdonalds.co.kr/www/kor/findus/district.do? pageIndex={ page }&sSearch_yn=Y&skey=2&skey1=&skey2=&skeyword={ location }
import requests
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
URI = 'http://www.mcdonalds.co.kr/www/kor/findus/district.do?pageIndex={page}&sSearch_yn=Y&skey=2&skey1=&skey2=&skeyword={location}'
URL = URI.format(
page=2,
location='서울특별시 종로구'
)
response = requests.get(URL)
response.url
'http://www.mcdonalds.co.kr/www/kor/findus/district.do?pageIndex=2&sSearch_yn=Y&skey=2&skey1=&skey2=&skeyword=%EC%84%9C%EC%9A%B8%ED%8A%B9%EB%B3%84%EC%8B%9C%20%EC%A2%85%EB%A1%9C%EA%B5%AC'
soup = BeautifulSoup(response.text, 'lxml')
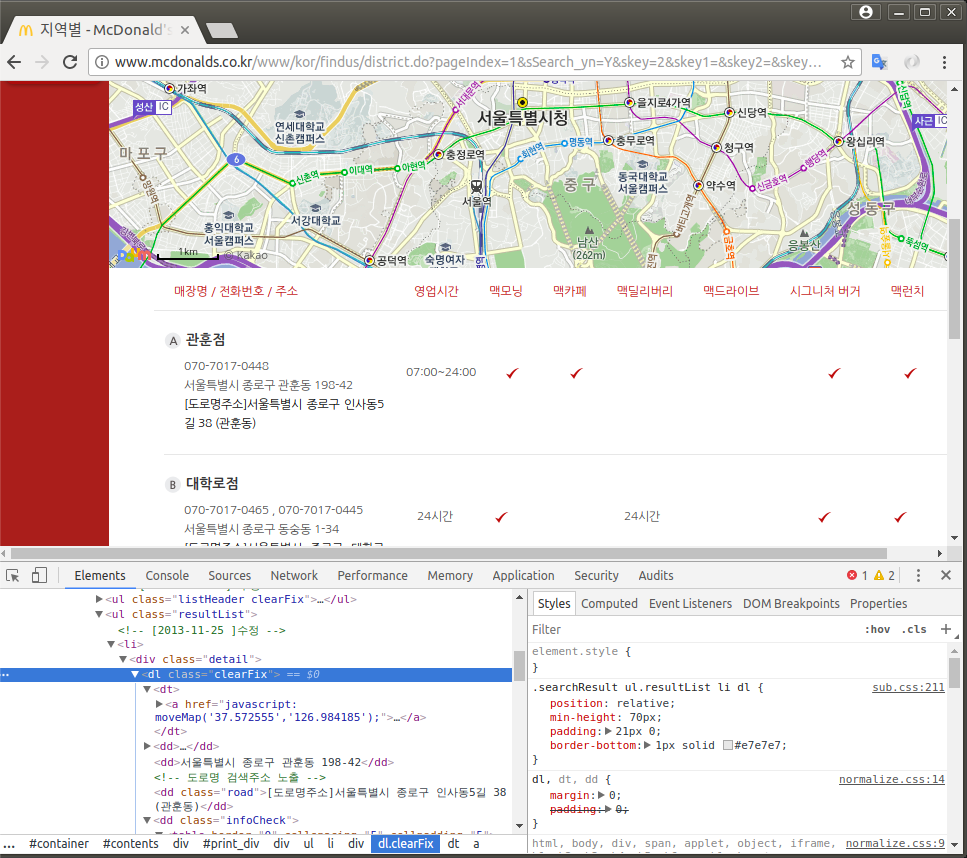
2) 매장 목록 부분 태그 + 빈 페이지 리스트
- 자치구 리스트 읽기
# 자치구 리스트
df = pd.read_csv('./data_ouput/02.crime_in_Seoul_final.csv')
McDonald_store = pd.DataFrame( {'구별' : df['구별'] } )
McDonald_store.head()
| 구별 | |
|---|---|
| 0 | 강남구 |
| 1 | 강동구 |
| 2 | 강북구 |
| 3 | 관악구 |
| 4 | 광진구 |
- 매장 목록 부분 태그
tmp = soup.find_all( 'dl', 'clearFix' )
tmp[0].a.get_text()
' 정동점'
- 빈 페이지 리스트
URI = 'http://www.mcdonalds.co.kr/www/kor/findus/district.do?pageIndex={page}&sSearch_yn=Y&skey=2&skey1=&skey2=&skeyword={location}'
URL = URI.format(
page=3,
location='서울특별시 종로구'
)
response = requests.get(URL)
soup = BeautifulSoup(response.text, 'lxml')
tmp = soup.find_all( 'dl', 'clearFix' )
tmp
[]
df.index
RangeIndex(start=0, stop=23, step=1)
import time
from itertools import count
URI = 'http://www.mcdonalds.co.kr/www/kor/findus/district.do?pageIndex={page}&sSearch_yn=Y&skey=2&skey1=&skey2=&skeyword={location}'
Mc_store_num = []
Mc_count = 0
for n in df.index:
time.sleep(0.5)
loc = '서울특별시' + ' ' + McDonald_store['구별'][n]
print('------------------------------------------------------------------------------------------')
print(loc)
print('------------------------------------------------------------------------------------------')
for pg in count():
time.sleep(0.5)
URL = URI.format(
page=pg+1,
location=loc
)
response = requests.get(URL)
soup = BeautifulSoup(response.text, 'lxml')
tmp = soup.find_all( 'dl', 'clearFix' )
print(pg, ' ➡ ', len(tmp))
Mc_count += len(tmp)
if len(tmp)==0:
Mc_store_num.append( Mc_count )
Mc_count = 0
break
------------------------------------------------------------------------------------------
서울특별시 강남구
------------------------------------------------------------------------------------------
0 ➡ 5
1 ➡ 5
2 ➡ 2
3 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 강동구
------------------------------------------------------------------------------------------
0 ➡ 5
1 ➡ 2
2 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 강북구
------------------------------------------------------------------------------------------
0 ➡ 5
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 관악구
------------------------------------------------------------------------------------------
0 ➡ 3
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 광진구
------------------------------------------------------------------------------------------
0 ➡ 2
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 구로구
------------------------------------------------------------------------------------------
0 ➡ 5
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 노원구
------------------------------------------------------------------------------------------
0 ➡ 5
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 도봉구
------------------------------------------------------------------------------------------
0 ➡ 2
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 동대문구
------------------------------------------------------------------------------------------
0 ➡ 5
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 동작구
------------------------------------------------------------------------------------------
0 ➡ 4
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 마포구
------------------------------------------------------------------------------------------
0 ➡ 5
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 서대문구
------------------------------------------------------------------------------------------
0 ➡ 4
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 서초구
------------------------------------------------------------------------------------------
0 ➡ 5
1 ➡ 1
2 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 성동구
------------------------------------------------------------------------------------------
0 ➡ 3
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 성북구
------------------------------------------------------------------------------------------
0 ➡ 4
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 송파구
------------------------------------------------------------------------------------------
0 ➡ 5
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 양천구
------------------------------------------------------------------------------------------
0 ➡ 5
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 영등포구
------------------------------------------------------------------------------------------
0 ➡ 5
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 용산구
------------------------------------------------------------------------------------------
0 ➡ 2
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 은평구
------------------------------------------------------------------------------------------
0 ➡ 4
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 종로구
------------------------------------------------------------------------------------------
0 ➡ 5
1 ➡ 2
2 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 중구
------------------------------------------------------------------------------------------
0 ➡ 3
1 ➡ 0
------------------------------------------------------------------------------------------
서울특별시 중랑구
------------------------------------------------------------------------------------------
0 ➡ 4
1 ➡ 0
McDonald_store['맥도널드매장수'] = Mc_store_num
McDonald_store.head()
| 구별 | 맥도널드매장수 | |
|---|---|---|
| 0 | 강남구 | 12 |
| 1 | 강동구 | 7 |
| 2 | 강북구 | 5 |
| 3 | 관악구 | 3 |
| 4 | 광진구 | 2 |
McDonald_store.set_index('구별', inplace=True)
McDonald_store.tail()
| 맥도널드매장수 | |
|---|---|
| 구별 | |
| 용산구 | 2 |
| 은평구 | 4 |
| 종로구 | 7 |
| 중구 | 3 |
| 중랑구 | 4 |
6. 네이버 영화 평점 사이트
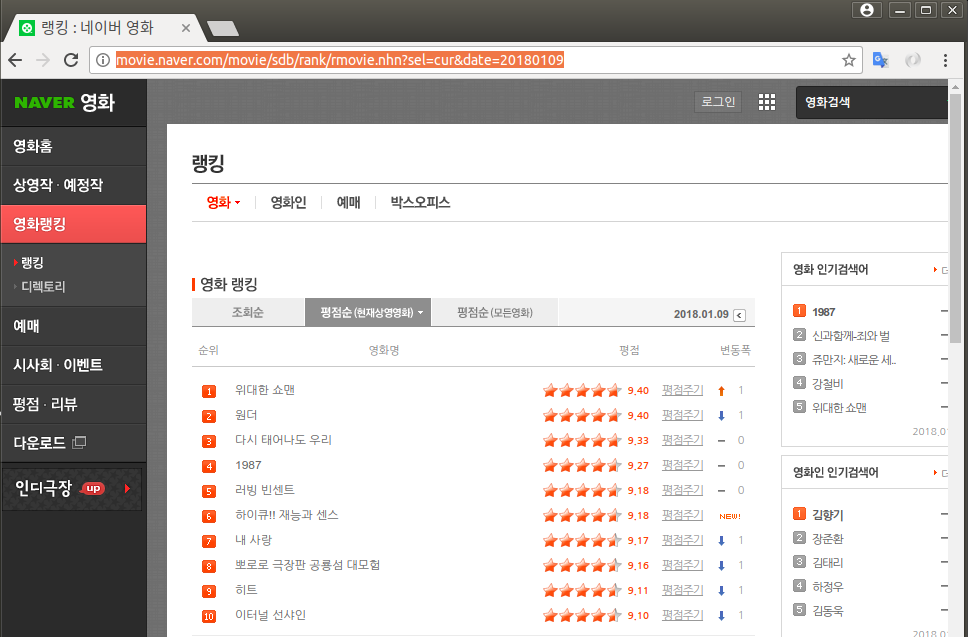
1) 날짜별 네이버 영화 평점 추이
- 날짜 -
pandas.date_range( 시작일, periods=기간, freq='D) - 기간 -
2017-5-1~2017-6-29
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = 'http://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=cur&date=20170704'
res = requests.get(url)
page = res.text
soup = BeautifulSoup(page, 'lxml')
# 영화 제목
soup.find_all('div', 'tit5')[0].a.text
'사운드 오브 뮤직'
# 영화 평점
soup.find_all('td', 'point')[0].text
'9.36'
movie_name = [ soup.find_all('div', 'tit5')[n].a.text for n in range(0, 49) ]
movie_name[:5]
['사운드 오브 뮤직', '킹 오브 프리즘 프라이드 더 히어로', '서서평, 천천히 평온하게', '첫 키스만 50번째', '우리들']
movie_point = [ soup.find_all('td', 'point')[n].text for n in range(0, 49) ]
movie_point[:5]
['9.36', '9.34', '9.23', '9.22', '9.19']
# 기간
date = pd.date_range('2017-5-1', periods=60, freq='D')
date
DatetimeIndex(['2017-05-01', '2017-05-02', '2017-05-03', '2017-05-04',
'2017-05-05', '2017-05-06', '2017-05-07', '2017-05-08',
'2017-05-09', '2017-05-10', '2017-05-11', '2017-05-12',
'2017-05-13', '2017-05-14', '2017-05-15', '2017-05-16',
'2017-05-17', '2017-05-18', '2017-05-19', '2017-05-20',
'2017-05-21', '2017-05-22', '2017-05-23', '2017-05-24',
'2017-05-25', '2017-05-26', '2017-05-27', '2017-05-28',
'2017-05-29', '2017-05-30', '2017-05-31', '2017-06-01',
'2017-06-02', '2017-06-03', '2017-06-04', '2017-06-05',
'2017-06-06', '2017-06-07', '2017-06-08', '2017-06-09',
'2017-06-10', '2017-06-11', '2017-06-12', '2017-06-13',
'2017-06-14', '2017-06-15', '2017-06-16', '2017-06-17',
'2017-06-18', '2017-06-19', '2017-06-20', '2017-06-21',
'2017-06-22', '2017-06-23', '2017-06-24', '2017-06-25',
'2017-06-26', '2017-06-27', '2017-06-28', '2017-06-29'],
dtype='datetime64[ns]', freq='D')
date[0].strftime('%Y%m%d')
'20170501'
url_date = 'http://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=cur&date={u_date}'
url = url_date.format( u_date = date[0].strftime('%Y%m%d') )
url
'http://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=cur&date=20170501'
movie_date = []
movie_name = []
movie_point = []
url_date = 'http://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=cur&date={date}'
for day in date:
u_date = day.strftime('%Y%m%d')
url = url_date.format(date=u_date)
res = requests.get(url)
html = res.text
soup = BeautifulSoup(html, 'lxml')
end = len( soup.find_all('td', 'point') )
movie_date.extend( [day for n in range(0, end)] )
movie_name.extend( [ soup.find_all('div', 'tit5')[n].a.text for n in range(0, end) ] )
movie_point.extend( [ soup.find_all('td', 'point')[n].text for n in range(0, end) ] )
len(movie_date), len(movie_name), len(movie_point)
(2793, 2793, 2793)
movie = pd.DataFrame(
{
'date': movie_date,
'name': movie_name,
'point': movie_point
}
)
movie.head()
| date | name | point | |
|---|---|---|---|
| 0 | 2017-05-01 | 히든 피겨스 | 9.38 |
| 1 | 2017-05-01 | 사운드 오브 뮤직 | 9.36 |
| 2 | 2017-05-01 | 시네마 천국 | 9.29 |
| 3 | 2017-05-01 | 미스 슬로운 | 9.26 |
| 4 | 2017-05-01 | 잉여들의 히치하이킹 | 9.25 |
# 데이터 유형 확인
movie.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2793 entries, 0 to 2792
Data columns (total 3 columns):
date 2793 non-null datetime64[ns]
name 2793 non-null object
point 2793 non-null object
dtypes: datetime64[ns](1), object(2)
memory usage: 65.5+ KB
# point를 float 형으로 변경
movie['point'] = movie['point'].astype(float)
movie.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2793 entries, 0 to 2792
Data columns (total 3 columns):
date 2793 non-null datetime64[ns]
name 2793 non-null object
point 2793 non-null float64
dtypes: datetime64[ns](1), float64(1), object(1)
memory usage: 65.5+ KB
import numpy as np
movie_unique = pd.pivot_table(
movie,
index=['name'],
aggfunc=np.sum
)
movie_best = movie_unique.sort_values( by='point', ascending=False )
movie_best.head()
| point | |
|---|---|
| name | |
| 댄서 | 548.91 |
| 서서평, 천천히 평온하게 | 520.33 |
| 오두막 | 520.29 |
| 라라랜드 | 515.29 |
| 보스 베이비 | 505.36 |
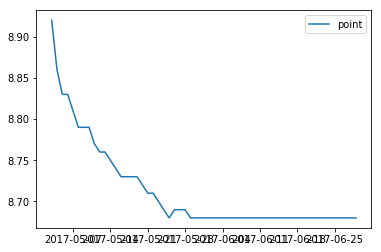
# 보스 베이비 평점 변화
tmp = movie.query('name == ["보스 베이비"]')
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure()
plt.plot( tmp['date'], tmp['point'] )
plt.legend(loc='best')
plt.show()
movie_pivot = pd.pivot_table(
movie,
index=["date"],
columns=["name"],
values=['point']
)
movie_pivot.head()
| point | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| name | 10분 | 7번째 내가 죽던 날 | 8 마일 | 가디언즈 오브 갤럭시 | 가디언즈 오브 갤럭시 VOL. 2 | 겟 아웃 | 공각기동대 : 고스트 인 더 쉘 | 그녀 | 그랑블루 | 그물 | ... | 피와 뼈 | 하루 | 하이큐!! 끝과 시작 | 한공주 | 해리가 샐리를 만났을 때 | 핵소 고지 | 행복 목욕탕 | 헤드윅 | 흑집사 : 북 오브 더 아틀란틱 | 히든 피겨스 |
| date | |||||||||||||||||||||
| 2017-05-01 | 8.89 | NaN | NaN | 8.56 | NaN | NaN | NaN | NaN | 8.78 | NaN | ... | NaN | NaN | NaN | 8.78 | 8.89 | NaN | 8.70 | NaN | 9.20 | 9.38 |
| 2017-05-02 | 8.89 | NaN | NaN | 8.56 | NaN | NaN | NaN | NaN | 8.78 | NaN | ... | NaN | NaN | NaN | 8.78 | 8.89 | NaN | 8.68 | NaN | 9.21 | 9.37 |
| 2017-05-03 | 8.89 | NaN | NaN | NaN | 9.22 | NaN | NaN | NaN | 8.78 | NaN | ... | NaN | NaN | NaN | 8.78 | 8.89 | NaN | 8.70 | NaN | 9.22 | 9.38 |
| 2017-05-04 | 8.89 | NaN | NaN | NaN | 9.15 | NaN | 7.18 | NaN | 8.78 | NaN | ... | NaN | NaN | NaN | 8.78 | NaN | NaN | 8.67 | NaN | 9.23 | 9.38 |
| 2017-05-05 | 8.89 | NaN | NaN | NaN | 9.08 | NaN | 7.16 | NaN | NaN | NaN | ... | NaN | NaN | NaN | 8.78 | NaN | NaN | 8.69 | NaN | 9.24 | 9.37 |
5 rows × 150 columns
movie_pivot.columns = movie_pivot.columns.droplevel()
movie_pivot.head()
| name | 10분 | 7번째 내가 죽던 날 | 8 마일 | 가디언즈 오브 갤럭시 | 가디언즈 오브 갤럭시 VOL. 2 | 겟 아웃 | 공각기동대 : 고스트 인 더 쉘 | 그녀 | 그랑블루 | 그물 | ... | 피와 뼈 | 하루 | 하이큐!! 끝과 시작 | 한공주 | 해리가 샐리를 만났을 때 | 핵소 고지 | 행복 목욕탕 | 헤드윅 | 흑집사 : 북 오브 더 아틀란틱 | 히든 피겨스 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||||||||||||
| 2017-05-01 | 8.89 | NaN | NaN | 8.56 | NaN | NaN | NaN | NaN | 8.78 | NaN | ... | NaN | NaN | NaN | 8.78 | 8.89 | NaN | 8.70 | NaN | 9.20 | 9.38 |
| 2017-05-02 | 8.89 | NaN | NaN | 8.56 | NaN | NaN | NaN | NaN | 8.78 | NaN | ... | NaN | NaN | NaN | 8.78 | 8.89 | NaN | 8.68 | NaN | 9.21 | 9.37 |
| 2017-05-03 | 8.89 | NaN | NaN | NaN | 9.22 | NaN | NaN | NaN | 8.78 | NaN | ... | NaN | NaN | NaN | 8.78 | 8.89 | NaN | 8.70 | NaN | 9.22 | 9.38 |
| 2017-05-04 | 8.89 | NaN | NaN | NaN | 9.15 | NaN | 7.18 | NaN | 8.78 | NaN | ... | NaN | NaN | NaN | 8.78 | NaN | NaN | 8.67 | NaN | 9.23 | 9.38 |
| 2017-05-05 | 8.89 | NaN | NaN | NaN | 9.08 | NaN | 7.16 | NaN | NaN | NaN | ... | NaN | NaN | NaN | 8.78 | NaN | NaN | 8.69 | NaN | 9.24 | 9.37 |
5 rows × 150 columns
# 한글 문제
import matplotlib.font_manager as fm
## 폰트 적용
font_location = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
font_name = fm.FontProperties(fname=font_location).get_name()
from matplotlib import rc
rc('font', family=font_name)
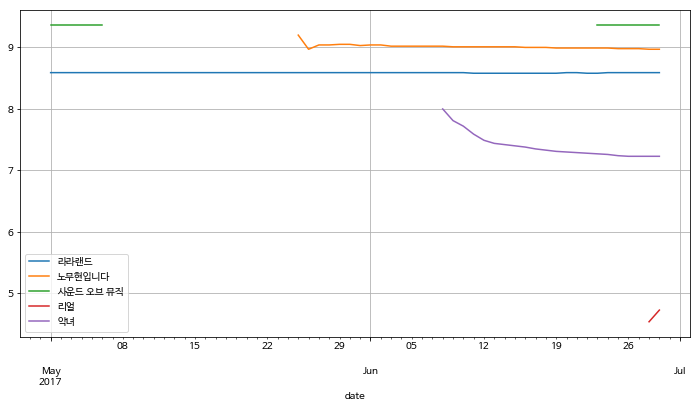
movie_pivot.plot(
y=["라라랜드", "노무현입니다", "사운드 오브 뮤직", '리얼', '악녀'],
figsize=(12, 6)
)
plt.legend(loc="best")
plt.grid()
plt.show()
/home/learn/.pyenv/versions/3.6.2/envs/Jupyter/lib/python3.6/site-packages/pandas/plotting/_core.py:1716: UserWarning: Pandas doesn't allow columns to be created via a new attribute name - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute-access
series.name = label