데이터 사이언스 02 검증- 강남3구의 안전도
- 1. 주장과 가설 - '부자 동네' … 서울 강남 3구 체감안전도 높아
- 2. 데이터 얻기
- 3. 데이터 가공
- 4. 데이터 분석 - 표
- 5. 시각화 1 - Heatmap
- 6. 소결 및 시각화 2 - Folium
1. 주장과 가설 - '부자 동네' … 서울 강남 3구 체감안전도 높아
1) 관련 기사
2) 가설 : 체감대로 실제 강남 3구는 안전한가?
- 가설에 대한 검증 설계
(1) 서울의 자치구 별 범죄율에 대한 데이터 획득하기
(2) 강남 3구와 비교하기 위해 자치구 별로 분류하기
(3) 비교 가능한 지표를 만들기
(4) 지도 시각화 - Seabon, Google Maps, Folium
2. 데이터 얻기
1) 서울특별시 관서별 5대 범죄 현황
import numpy as np
import pandas as pd
police_station = pd.read_csv(
'./data_science/02. crime_in_Seoul.csv',
thousands=',',
encoding='euc-kr'
)
police_station.head()
| 관서명 | 살인 발생 | 살인 검거 | 강도 발생 | 강도 검거 | 강간 발생 | 강간 검거 | 절도 발생 | 절도 검거 | 폭력 발생 | 폭력 검거 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 중부서 | 2 | 2 | 3 | 2 | 105 | 65 | 1395 | 477 | 1355 | 1170 |
| 1 | 종로서 | 3 | 3 | 6 | 5 | 115 | 98 | 1070 | 413 | 1278 | 1070 |
| 2 | 남대문서 | 1 | 0 | 6 | 4 | 65 | 46 | 1153 | 382 | 869 | 794 |
| 3 | 서대문서 | 2 | 2 | 5 | 4 | 154 | 124 | 1812 | 738 | 2056 | 1711 |
| 4 | 혜화서 | 3 | 2 | 5 | 4 | 96 | 63 | 1114 | 424 | 1015 | 861 |
2) 경찰서별 소속 자치구 확인하기
-
웹 서비스 > Google Maps Geocoding API > API Key:
-
googlemaps
$ pip install googlemaps
import googlemaps
gmaps = googlemaps.Client(key="AIzaSyC58AWrye6Z-2vAdoEVv_Xsf6sk6Vsg_90")
- 자료 1개의 데이터 구조 파악 : 서울중부경찰서
gmaps.geocode('서울중부경찰서', language='ko')
[{'address_components': [{'long_name': '27',
'short_name': '27',
'types': ['political', 'premise']},
{'long_name': '수표로',
'short_name': '수표로',
'types': ['political', 'sublocality', 'sublocality_level_4']},
{'long_name': '을지로동',
'short_name': '을지로동',
'types': ['political', 'sublocality', 'sublocality_level_2']},
{'long_name': '중구',
'short_name': '중구',
'types': ['political', 'sublocality', 'sublocality_level_1']},
{'long_name': '서울특별시',
'short_name': '서울특별시',
'types': ['administrative_area_level_1', 'political']},
{'long_name': '대한민국',
'short_name': 'KR',
'types': ['country', 'political']},
{'long_name': '100-032',
'short_name': '100-032',
'types': ['postal_code']}],
'formatted_address': '대한민국 서울특별시 중구 을지로동 수표로 27',
'geometry': {'location': {'lat': 37.5636465, 'lng': 126.9895796},
'location_type': 'ROOFTOP',
'viewport': {'northeast': {'lat': 37.56499548029149,
'lng': 126.9909285802915},
'southwest': {'lat': 37.56229751970849, 'lng': 126.9882306197085}}},
'place_id': 'ChIJc-9q5uSifDURLhQmr5wkXmc',
'types': ['establishment', 'point_of_interest', 'police']}]
# 자료 형태 파악 : 리스트 [ 딕셔너리 { key : value } ]
tmp = gmaps.geocode('서울종로경찰서', language='ko')[0].get('formatted_address')
tmp.split()
['대한민국', '서울특별시', '종로구', '종로1.2.3.4가동', '율곡로', '46']
# 구 이름 얻기
[ name for name in tmp.split() if name[-1] == '구' ]
['종로구']
- 경찰서 검색어 완성하기
station_name=[]
for name in police_station['관서명']:
station_name.append( '서울' + str(name[:-1]) + '경찰서' )
station_name[0:5]
['서울중부경찰서', '서울종로경찰서', '서울남대문경찰서', '서울서대문경찰서', '서울혜화경찰서']
- 경찰서 검색어로 경찰서 소재 자치구 이름 얻기
station_address = []
station_lat = []
station_lng = []
for name in station_name:
tmp = gmaps.geocode(name, language='ko')
# 경찰서 주소 얻기
station_address.append(tmp[0].get('formatted_address'))
tmp_loc = tmp[0].get("geometry")
# 경찰서 위치 얻기
station_lat.append(tmp_loc['location']['lat'])
station_lng.append(tmp_loc['location']['lng'])
station_address[0:5]
['대한민국 서울특별시 중구 을지로동 수표로 27',
'대한민국 서울특별시 종로구 종로1.2.3.4가동 율곡로 46',
'대한민국 서울특별시 중구 남대문로5가 한강대로 410',
'대한민국 서울특별시 서대문구 미근동 통일로 113',
'대한민국 서울특별시 종로구 종로1.2.3.4가동 창경궁로 112-16']
station_lat[0:5]
[37.5636465, 37.5755578, 37.5547584, 37.5647848, 37.5718401]
station_lng[0:5]
[126.9895796, 126.9848674, 126.9734981, 126.9667762, 126.9988562]
# 구 이름 얻기
gu_name = []
for name in station_address:
tmp = name.split()
tmp_gu = [ gu for gu in tmp if gu[-1] == '구'][0]
gu_name.append(tmp_gu)
gu_name[20:-1]
['강동구', '성북구', '구로구', '서초구', '양천구', '송파구', '노원구', '서초구', '은평구', '도봉구']
# 구 이름을 붙이기
police_station['구별'] = gu_name
police_station.head()
| 관서명 | 살인 발생 | 살인 검거 | 강도 발생 | 강도 검거 | 강간 발생 | 강간 검거 | 절도 발생 | 절도 검거 | 폭력 발생 | 폭력 검거 | 구별 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 중부서 | 2 | 2 | 3 | 2 | 105 | 65 | 1395 | 477 | 1355 | 1170 | 중구 |
| 1 | 종로서 | 3 | 3 | 6 | 5 | 115 | 98 | 1070 | 413 | 1278 | 1070 | 종로구 |
| 2 | 남대문서 | 1 | 0 | 6 | 4 | 65 | 46 | 1153 | 382 | 869 | 794 | 중구 |
| 3 | 서대문서 | 2 | 2 | 5 | 4 | 154 | 124 | 1812 | 738 | 2056 | 1711 | 서대문구 |
| 4 | 혜화서 | 3 | 2 | 5 | 4 | 96 | 63 | 1114 | 424 | 1015 | 861 | 종로구 |
3. 데이터 가공
1) 자치구 기준으로 범죄 발생/검거 데이터 정리하기
# 중간 데이터 저장
police_station.to_csv(
'./data_ouput/02.crime_in_Seoul_including_gu_name.csv',
sep=',',
encoding='utf-8'
)
- 관서명기준에서 구별기준으로 바꾸기 : Pandas의 pivot_table기능 이용하기
gu_criminal_raw = pd.read_csv(
'./data_ouput/02.crime_in_Seoul_including_gu_name.csv',
encoding='utf-8',
index_col=0
)
gu_criminal_raw.head()
| 관서명 | 살인 발생 | 살인 검거 | 강도 발생 | 강도 검거 | 강간 발생 | 강간 검거 | 절도 발생 | 절도 검거 | 폭력 발생 | 폭력 검거 | 구별 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 중부서 | 2 | 2 | 3 | 2 | 105 | 65 | 1395 | 477 | 1355 | 1170 | 중구 |
| 1 | 종로서 | 3 | 3 | 6 | 5 | 115 | 98 | 1070 | 413 | 1278 | 1070 | 종로구 |
| 2 | 남대문서 | 1 | 0 | 6 | 4 | 65 | 46 | 1153 | 382 | 869 | 794 | 중구 |
| 3 | 서대문서 | 2 | 2 | 5 | 4 | 154 | 124 | 1812 | 738 | 2056 | 1711 | 서대문구 |
| 4 | 혜화서 | 3 | 2 | 5 | 4 | 96 | 63 | 1114 | 424 | 1015 | 861 | 종로구 |
gu_criminal = pd.pivot_table(
gu_criminal_raw,
index='구별',
aggfunc=np.sum
)
gu_criminal.head()
| 강간 검거 | 강간 발생 | 강도 검거 | 강도 발생 | 살인 검거 | 살인 발생 | 절도 검거 | 절도 발생 | 폭력 검거 | 폭력 발생 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 구별 | ||||||||||
| 강남구 | 349 | 449 | 18 | 21 | 10 | 13 | 1650 | 3850 | 3705 | 4284 |
| 강동구 | 123 | 156 | 8 | 6 | 3 | 4 | 789 | 2366 | 2248 | 2712 |
| 강북구 | 126 | 153 | 13 | 14 | 8 | 7 | 618 | 1434 | 2348 | 2649 |
| 관악구 | 343 | 471 | 20 | 18 | 12 | 12 | 1715 | 4273 | 4418 | 5352 |
| 광진구 | 220 | 240 | 26 | 14 | 4 | 4 | 1277 | 3026 | 2180 | 2625 |
2) 위 데이터의 문제점
- 살인과 절도가 서로 비교할 수 있는 범죄인가?
- 치안(검거)의 관점에서 살인 건수와 절도 건수의 격차 (100배에서 1,000배 차이) 를 어떻게 처리할 것인가?
3) 검거율
gu_criminal['강간검거율'] = gu_criminal['강간 검거']/gu_criminal['강간 발생'] * 100
gu_criminal['강도검거율'] = gu_criminal['강도 검거']/gu_criminal['강도 발생'] * 100
gu_criminal['살인검거율'] = gu_criminal['살인 검거']/gu_criminal['살인 발생'] * 100
gu_criminal['절도검거율'] = gu_criminal['절도 검거']/gu_criminal['절도 발생'] * 100
gu_criminal['폭력검거율'] = gu_criminal['폭력 검거']/gu_criminal['폭력 발생'] * 100
gu_criminal.head()
| 강간 검거 | 강간 발생 | 강도 검거 | 강도 발생 | 살인 검거 | 살인 발생 | 절도 검거 | 절도 발생 | 폭력 검거 | 폭력 발생 | 강간검거율 | 강도검거율 | 살인검거율 | 절도검거율 | 폭력검거율 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 구별 | |||||||||||||||
| 강남구 | 349 | 449 | 18 | 21 | 10 | 13 | 1650 | 3850 | 3705 | 4284 | 77.728285 | 85.714286 | 76.923077 | 42.857143 | 86.484594 |
| 강동구 | 123 | 156 | 8 | 6 | 3 | 4 | 789 | 2366 | 2248 | 2712 | 78.846154 | 133.333333 | 75.000000 | 33.347422 | 82.890855 |
| 강북구 | 126 | 153 | 13 | 14 | 8 | 7 | 618 | 1434 | 2348 | 2649 | 82.352941 | 92.857143 | 114.285714 | 43.096234 | 88.637222 |
| 관악구 | 343 | 471 | 20 | 18 | 12 | 12 | 1715 | 4273 | 4418 | 5352 | 72.823779 | 111.111111 | 100.000000 | 40.135736 | 82.548580 |
| 광진구 | 220 | 240 | 26 | 14 | 4 | 4 | 1277 | 3026 | 2180 | 2625 | 91.666667 | 185.714286 | 100.000000 | 42.200925 | 83.047619 |
- 검거율이 100%를 넘는 데이터가 있다.
gu_criminal[ gu_criminal[[ '강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율' ]] > 100 ] = 100
gu_criminal.head()
| 강간 검거 | 강간 발생 | 강도 검거 | 강도 발생 | 살인 검거 | 살인 발생 | 절도 검거 | 절도 발생 | 폭력 검거 | 폭력 발생 | 강간검거율 | 강도검거율 | 살인검거율 | 절도검거율 | 폭력검거율 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 구별 | |||||||||||||||
| 강남구 | 349 | 449 | 18 | 21 | 10 | 13 | 1650 | 3850 | 3705 | 4284 | 77.728285 | 85.714286 | 76.923077 | 42.857143 | 86.484594 |
| 강동구 | 123 | 156 | 8 | 6 | 3 | 4 | 789 | 2366 | 2248 | 2712 | 78.846154 | 100.000000 | 75.000000 | 33.347422 | 82.890855 |
| 강북구 | 126 | 153 | 13 | 14 | 8 | 7 | 618 | 1434 | 2348 | 2649 | 82.352941 | 92.857143 | 100.000000 | 43.096234 | 88.637222 |
| 관악구 | 343 | 471 | 20 | 18 | 12 | 12 | 1715 | 4273 | 4418 | 5352 | 72.823779 | 100.000000 | 100.000000 | 40.135736 | 82.548580 |
| 광진구 | 220 | 240 | 26 | 14 | 4 | 4 | 1277 | 3026 | 2180 | 2625 | 91.666667 | 100.000000 | 100.000000 | 42.200925 | 83.047619 |
del gu_criminal['강간 검거']
del gu_criminal['강도 검거']
del gu_criminal['살인 검거']
del gu_criminal['절도 검거']
del gu_criminal['폭력 검거']
gu_criminal.head()
| 강간 발생 | 강도 발생 | 살인 발생 | 절도 발생 | 폭력 발생 | 강간검거율 | 강도검거율 | 살인검거율 | 절도검거율 | 폭력검거율 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 구별 | ||||||||||
| 강남구 | 449 | 21 | 13 | 3850 | 4284 | 77.728285 | 85.714286 | 76.923077 | 42.857143 | 86.484594 |
| 강동구 | 156 | 6 | 4 | 2366 | 2712 | 78.846154 | 100.000000 | 75.000000 | 33.347422 | 82.890855 |
| 강북구 | 153 | 14 | 7 | 1434 | 2649 | 82.352941 | 92.857143 | 100.000000 | 43.096234 | 88.637222 |
| 관악구 | 471 | 18 | 12 | 4273 | 5352 | 72.823779 | 100.000000 | 100.000000 | 40.135736 | 82.548580 |
| 광진구 | 240 | 14 | 4 | 3026 | 2625 | 91.666667 | 100.000000 | 100.000000 | 42.200925 | 83.047619 |
gu_criminal.rename( columns={'강간 발생' : '강간',
'강도 발생' : '강도',
'살인 발생' : '살인',
'절도 발생' : '절도',
'폭력 발생' : '폭력' },
inplace=True
)
gu_criminal.head()
| 강간 | 강도 | 살인 | 절도 | 폭력 | 강간검거율 | 강도검거율 | 살인검거율 | 절도검거율 | 폭력검거율 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 구별 | ||||||||||
| 강남구 | 449 | 21 | 13 | 3850 | 4284 | 77.728285 | 85.714286 | 76.923077 | 42.857143 | 86.484594 |
| 강동구 | 156 | 6 | 4 | 2366 | 2712 | 78.846154 | 100.000000 | 75.000000 | 33.347422 | 82.890855 |
| 강북구 | 153 | 14 | 7 | 1434 | 2649 | 82.352941 | 92.857143 | 100.000000 | 43.096234 | 88.637222 |
| 관악구 | 471 | 18 | 12 | 4273 | 5352 | 72.823779 | 100.000000 | 100.000000 | 40.135736 | 82.548580 |
| 광진구 | 240 | 14 | 4 | 3026 | 2625 | 91.666667 | 100.000000 | 100.000000 | 42.200925 | 83.047619 |
4) 데이터 normalization
gu_criminal_norm = gu_criminal[['강간', '강도', '살인', '절도', '폭력' ]]/gu_criminal[['강간', '강도', '살인', '절도', '폭력' ]].max()
gu_criminal_norm[[ '강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율' ]] = \
gu_criminal[[ '강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율' ]]
gu_criminal_norm.head()
| 강간 | 강도 | 살인 | 절도 | 폭력 | 강간검거율 | 강도검거율 | 살인검거율 | 절도검거율 | 폭력검거율 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 구별 | ||||||||||
| 강남구 | 0.953291 | 0.954545 | 0.928571 | 0.901006 | 0.749475 | 77.728285 | 85.714286 | 76.923077 | 42.857143 | 86.484594 |
| 강동구 | 0.331210 | 0.272727 | 0.285714 | 0.553709 | 0.474458 | 78.846154 | 100.000000 | 75.000000 | 33.347422 | 82.890855 |
| 강북구 | 0.324841 | 0.636364 | 0.500000 | 0.335596 | 0.463436 | 82.352941 | 92.857143 | 100.000000 | 43.096234 | 88.637222 |
| 관악구 | 1.000000 | 0.818182 | 0.857143 | 1.000000 | 0.936319 | 72.823779 | 100.000000 | 100.000000 | 40.135736 | 82.548580 |
| 광진구 | 0.509554 | 0.636364 | 0.285714 | 0.708168 | 0.459237 | 91.666667 | 100.000000 | 100.000000 | 42.200925 | 83.047619 |
5) 인구 및 cctv 현황 데이터와 결합하기
# 인구 및 cctv 현황 데이터 읽기
result_CCTV = pd.read_csv(
'./data_ouput/01.CCTV_result.csv',
encoding='utf-8',
index_col='구별',
)
result_CCTV.head()
| 소계 | 최근증가율 | 인구수 | 한국인 | 외국인 | 고령자 | 외국인비율 | 고령자비율 | CCTV비율 | 오차 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 구별 | ||||||||||
| 강남구 | 3238 | 150.619195 | 565731.0 | 560827.0 | 4904.0 | 64579.0 | 0.866843 | 11.415143 | 0.572357 | 1543.390613 |
| 양천구 | 2482 | 34.671731 | 476627.0 | 472730.0 | 3897.0 | 54598.0 | 0.817620 | 11.455079 | 0.520743 | 887.616126 |
| 강서구 | 911 | 134.793814 | 607877.0 | 601391.0 | 6486.0 | 75046.0 | 1.066992 | 12.345590 | 0.149866 | 831.015839 |
| 용산구 | 2096 | 53.216374 | 243922.0 | 228960.0 | 14962.0 | 36727.0 | 6.133928 | 15.056862 | 0.859291 | 763.366194 |
| 서초구 | 2297 | 63.371266 | 447177.0 | 442833.0 | 4344.0 | 52738.0 | 0.971427 | 11.793540 | 0.513667 | 735.741927 |
# 구별 범죄 데이터에 인구 및 CCTV 현황 데이터 중 '인구수'/'소계' 붙이기
gu_criminal_norm[['인구수', 'CCTV']] = result_CCTV[['인구수', '소계']]
gu_criminal_norm.head()
| 강간 | 강도 | 살인 | 절도 | 폭력 | 강간검거율 | 강도검거율 | 살인검거율 | 절도검거율 | 폭력검거율 | 인구수 | CCTV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 구별 | ||||||||||||
| 강남구 | 0.953291 | 0.954545 | 0.928571 | 0.901006 | 0.749475 | 77.728285 | 85.714286 | 76.923077 | 42.857143 | 86.484594 | 565731.0 | 3238 |
| 강동구 | 0.331210 | 0.272727 | 0.285714 | 0.553709 | 0.474458 | 78.846154 | 100.000000 | 75.000000 | 33.347422 | 82.890855 | 446760.0 | 1010 |
| 강북구 | 0.324841 | 0.636364 | 0.500000 | 0.335596 | 0.463436 | 82.352941 | 92.857143 | 100.000000 | 43.096234 | 88.637222 | 329042.0 | 831 |
| 관악구 | 1.000000 | 0.818182 | 0.857143 | 1.000000 | 0.936319 | 72.823779 | 100.000000 | 100.000000 | 40.135736 | 82.548580 | 522849.0 | 2109 |
| 광진구 | 0.509554 | 0.636364 | 0.285714 | 0.708168 | 0.459237 | 91.666667 | 100.000000 | 100.000000 | 42.200925 | 83.047619 | 372414.0 | 878 |
4. 데이터 분석 - 표
1) 살인 사건이 많이 발생하는 구
gu_criminal_norm.sort_values(
by='살인',
ascending=False
).head()
| 강간 | 강도 | 살인 | 절도 | 폭력 | 강간검거율 | 강도검거율 | 살인검거율 | 절도검거율 | 폭력검거율 | 인구수 | CCTV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 구별 | ||||||||||||
| 영등포구 | 0.626327 | 1.000000 | 1.000000 | 0.693658 | 0.624913 | 62.033898 | 90.909091 | 85.714286 | 32.995951 | 82.894737 | 401908.0 | 1277 |
| 강남구 | 0.953291 | 0.954545 | 0.928571 | 0.901006 | 0.749475 | 77.728285 | 85.714286 | 76.923077 | 42.857143 | 86.484594 | 565731.0 | 3238 |
| 중랑구 | 0.397028 | 0.500000 | 0.928571 | 0.499649 | 0.498076 | 79.144385 | 81.818182 | 92.307692 | 38.829040 | 84.545135 | 414554.0 | 916 |
| 관악구 | 1.000000 | 0.818182 | 0.857143 | 1.000000 | 0.936319 | 72.823779 | 100.000000 | 100.000000 | 40.135736 | 82.548580 | 522849.0 | 2109 |
| 송파구 | 0.467091 | 0.590909 | 0.785714 | 0.758015 | 0.576452 | 80.909091 | 76.923077 | 90.909091 | 34.856437 | 84.552352 | 668366.0 | 1081 |
2) 강도 사건이 많이 발생하는 구
gu_criminal_norm.sort_values(
by='강도',
ascending=False
).head()
| 강간 | 강도 | 살인 | 절도 | 폭력 | 강간검거율 | 강도검거율 | 살인검거율 | 절도검거율 | 폭력검거율 | 인구수 | CCTV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 구별 | ||||||||||||
| 영등포구 | 0.626327 | 1.000000 | 1.000000 | 0.693658 | 0.624913 | 62.033898 | 90.909091 | 85.714286 | 32.995951 | 82.894737 | 401908.0 | 1277 |
| 강남구 | 0.953291 | 0.954545 | 0.928571 | 0.901006 | 0.749475 | 77.728285 | 85.714286 | 76.923077 | 42.857143 | 86.484594 | 565731.0 | 3238 |
| 양천구 | 0.811040 | 0.863636 | 0.714286 | 0.932834 | 1.000000 | 77.486911 | 84.210526 | 100.000000 | 48.469644 | 83.065080 | 476627.0 | 2482 |
| 관악구 | 1.000000 | 0.818182 | 0.857143 | 1.000000 | 0.936319 | 72.823779 | 100.000000 | 100.000000 | 40.135736 | 82.548580 | 522849.0 | 2109 |
| 구로구 | 0.596603 | 0.681818 | 0.571429 | 0.546454 | 0.526067 | 58.362989 | 73.333333 | 75.000000 | 38.072805 | 80.877951 | 443288.0 | 1884 |
3) 5대 범죄가 많이 발생하는 구
gu_criminal_norm['범죄'] = np.sum( gu_criminal_norm[['강간', '강도', '살인', '절도', '폭력' ]], axis=1 )
gu_criminal_norm.sort_values(
by='범죄',
ascending=False
).head()
| 강간 | 강도 | 살인 | 절도 | 폭력 | 강간검거율 | 강도검거율 | 살인검거율 | 절도검거율 | 폭력검거율 | 인구수 | CCTV | 범죄 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 구별 | |||||||||||||
| 관악구 | 1.000000 | 0.818182 | 0.857143 | 1.000000 | 0.936319 | 72.823779 | 100.000000 | 100.000000 | 40.135736 | 82.548580 | 522849.0 | 2109 | 4.611644 |
| 강남구 | 0.953291 | 0.954545 | 0.928571 | 0.901006 | 0.749475 | 77.728285 | 85.714286 | 76.923077 | 42.857143 | 86.484594 | 565731.0 | 3238 | 4.486889 |
| 양천구 | 0.811040 | 0.863636 | 0.714286 | 0.932834 | 1.000000 | 77.486911 | 84.210526 | 100.000000 | 48.469644 | 83.065080 | 476627.0 | 2482 | 4.321796 |
| 영등포구 | 0.626327 | 1.000000 | 1.000000 | 0.693658 | 0.624913 | 62.033898 | 90.909091 | 85.714286 | 32.995951 | 82.894737 | 401908.0 | 1277 | 3.944897 |
| 송파구 | 0.467091 | 0.590909 | 0.785714 | 0.758015 | 0.576452 | 80.909091 | 76.923077 | 90.909091 | 34.856437 | 84.552352 | 668366.0 | 1081 | 3.178182 |
4) 검거율이 높은 구
gu_criminal_norm['검거'] = np.sum( gu_criminal_norm[['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율' ]], axis=1 )
gu_criminal_norm.sort_values(
by='검거',
ascending=False
).head()
| 강간 | 강도 | 살인 | 절도 | 폭력 | 강간검거율 | 강도검거율 | 살인검거율 | 절도검거율 | 폭력검거율 | 인구수 | CCTV | 범죄 | 검거 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 구별 | ||||||||||||||
| 도봉구 | 0.216561 | 0.409091 | 0.214286 | 0.248771 | 0.260147 | 100.000000 | 100.000000 | 100.0 | 44.967074 | 87.626093 | 347338.0 | 825 | 1.348855 | 432.593167 |
| 광진구 | 0.509554 | 0.636364 | 0.285714 | 0.708168 | 0.459237 | 91.666667 | 100.000000 | 100.0 | 42.200925 | 83.047619 | 372414.0 | 878 | 2.599037 | 416.915211 |
| 동대문구 | 0.367304 | 0.590909 | 0.357143 | 0.463609 | 0.445766 | 84.393064 | 100.000000 | 100.0 | 41.090358 | 87.401884 | 367769.0 | 1870 | 2.224731 | 412.885306 |
| 용산구 | 0.411890 | 0.636364 | 0.357143 | 0.364381 | 0.358642 | 89.175258 | 100.000000 | 100.0 | 37.700706 | 83.121951 | 243922.0 | 2096 | 2.128419 | 409.997915 |
| 성동구 | 0.267516 | 0.409091 | 0.285714 | 0.376082 | 0.282015 | 94.444444 | 88.888889 | 100.0 | 37.149969 | 86.538462 | 312933.0 | 1327 | 1.620419 | 407.021764 |
5) 데이터 간 상관관계
np.corrcoef( gu_criminal_norm['범죄'], gu_criminal_norm['인구수'] )
array([[ 1. , 0.49350266],
[ 0.49350266, 1. ]])
np.corrcoef( gu_criminal_norm['검거'], gu_criminal_norm['인구수'] )
array([[ 1. , -0.01502092],
[-0.01502092, 1. ]])
np.corrcoef( gu_criminal_norm['살인'], gu_criminal_norm['폭력'] )
array([[ 1. , 0.69507356],
[ 0.69507356, 1. ]])
5. 시각화 1 - Heatmap
1) 표 데이터 분석의 문제점
- 한 눈에 데이터의 경향과 상관관계를 **알 수 없다. **
2) SEABORN 설치
- https://seaborn.pydata.org/
- Seaborn: statistical data visualization
- 설치
➯ pip install seaborn
Collecting seaborn
Downloading seaborn-0.8.1.tar.gz (178kB)
100% |████████████████████████████████| 184kB 1.1MB/s
Collecting scipy (from seaborn)
Downloading scipy-1.0.0-cp36-cp36m-manylinux1_x86_64.whl (50.0MB)
100% |████████████████████████████████| 50.0MB 19kB/s
Requirement already satisfied: numpy>=1.8.2 in /home/learn/.pyenv/versions/3.6.2/envs/Jupyter/lib/python3.6/site-packages (from scipy->seaborn)
Installing collected packages: scipy, seaborn
Running setup.py install for seaborn ... done
Successfully installed scipy-1.0.0 seaborn-0.8.1
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 한글 문제
import matplotlib.font_manager as fm
# 폰트 적용
font_location = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
font_name = fm.FontProperties(fname=font_location).get_name()
from matplotlib import rc
rc('font', family=font_name)
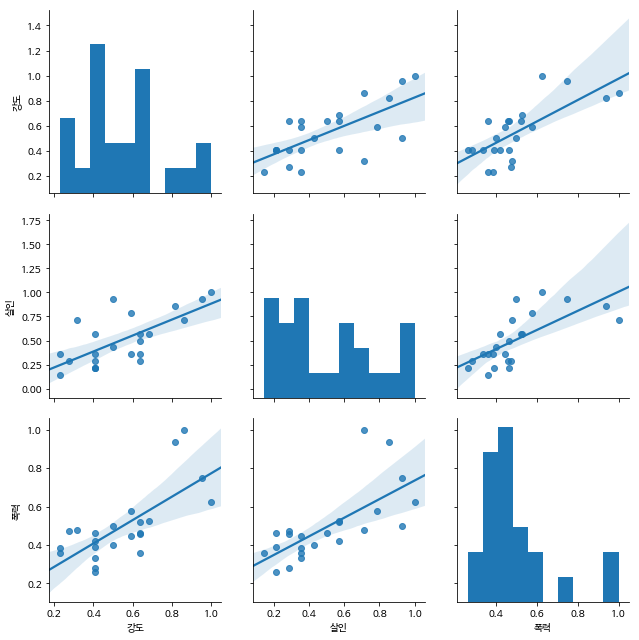
3) pairplot으로 데이터를 한 눈에 보기
- 강도, 살인, 폭력은 서로 상관관계가 있다.
sns.pairplot(
gu_criminal_norm,
vars=['강도', '살인', '폭력' ],
kind='reg',
size=3
)
plt.show()
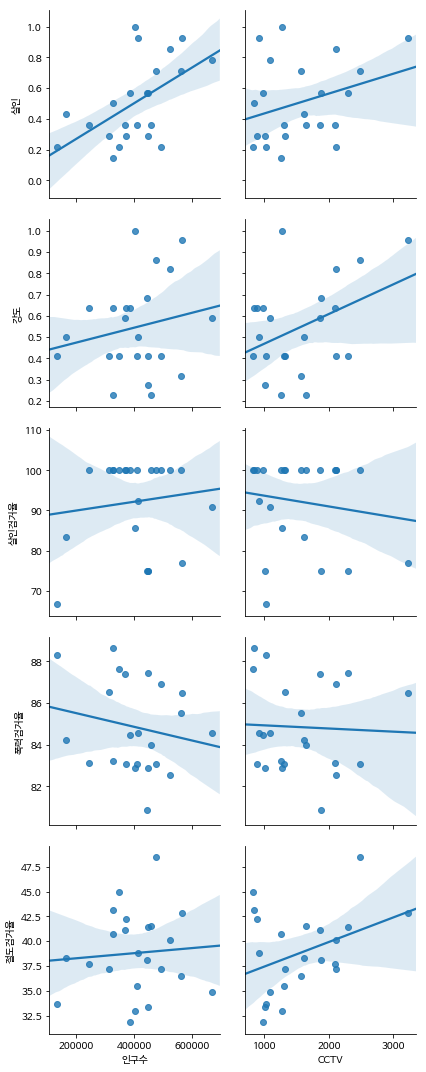
4) CCTV와의 관계
- CCTV숫자가 늘어날수록 살인, 강도가 낮아지고 살인검거율/강도검거율이 높아져야 하는데 실제로는,
❶ 살인, 강도가 높아지는 경향이 있으며,
➁ 살인검거율, 강도검거율이 높아지지 않는다.
- 그러나 절도검거율은 CCTV의 숫자에 비례하여 높아지는 경향이 있다.
sns.pairplot(
gu_criminal_norm,
x_vars=[ '인구수', 'CCTV' ],
y_vars=[ '살인', '강도', '살인검거율', '폭력검거율', '절도검거율' ],
kind='reg',
size=3
)
plt.show()
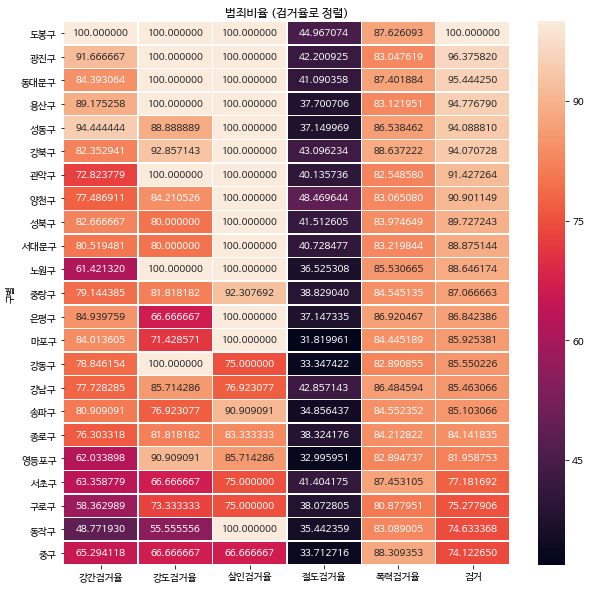
5) heatmap으로 데이터 한 눈에 보기
(1) 검거율 기준
- '검거' 부분 normalize
- heatmap으로 보기
- 다른 범죄에 비해 절도는 검거율이 낮다
- 동작, 서초, 송파, 강남구 모두 검거율이 낮다.
gu_criminal_norm['검거'] = gu_criminal_norm['검거']/gu_criminal_norm['검거'].max() * 100
gu_criminal_norm_sort = gu_criminal_norm.sort_values(
by='검거',
ascending=False
)
gu_criminal_norm_sort.head()
| 강간 | 강도 | 살인 | 절도 | 폭력 | 강간검거율 | 강도검거율 | 살인검거율 | 절도검거율 | 폭력검거율 | 인구수 | CCTV | 범죄 | 검거 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 구별 | ||||||||||||||
| 도봉구 | 0.216561 | 0.409091 | 0.214286 | 0.248771 | 0.260147 | 100.000000 | 100.000000 | 100.0 | 44.967074 | 87.626093 | 347338.0 | 825 | 1.348855 | 100.00000 |
| 광진구 | 0.509554 | 0.636364 | 0.285714 | 0.708168 | 0.459237 | 91.666667 | 100.000000 | 100.0 | 42.200925 | 83.047619 | 372414.0 | 878 | 2.599037 | 96.37582 |
| 동대문구 | 0.367304 | 0.590909 | 0.357143 | 0.463609 | 0.445766 | 84.393064 | 100.000000 | 100.0 | 41.090358 | 87.401884 | 367769.0 | 1870 | 2.224731 | 95.44425 |
| 용산구 | 0.411890 | 0.636364 | 0.357143 | 0.364381 | 0.358642 | 89.175258 | 100.000000 | 100.0 | 37.700706 | 83.121951 | 243922.0 | 2096 | 2.128419 | 94.77679 |
| 성동구 | 0.267516 | 0.409091 | 0.285714 | 0.376082 | 0.282015 | 94.444444 | 88.888889 | 100.0 | 37.149969 | 86.538462 | 312933.0 | 1327 | 1.620419 | 94.08881 |
target_col = [ '강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율', '검거' ]
plt.figure( figsize=(10, 10) )
sns.heatmap( gu_criminal_norm_sort[target_col], annot=True, fmt='f', linewidths=.5 )
plt.title( '범죄비율 (정규화된 검거율로 정렬)')
plt.show()
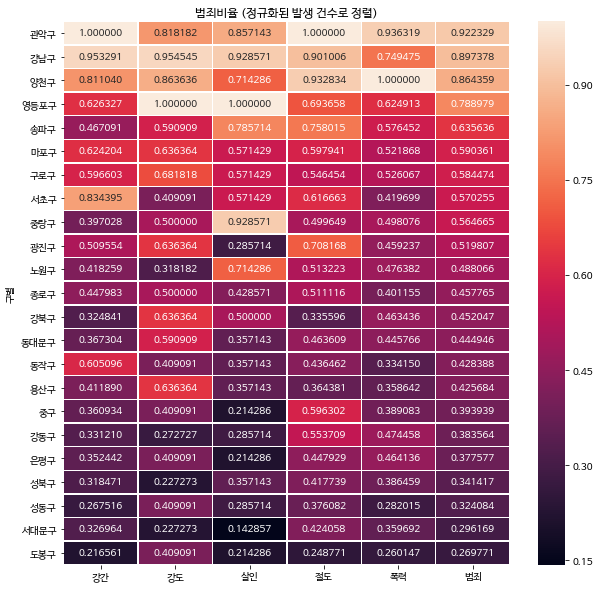
(2) 범죄 발생 건수 기준
- 강남, 송파, 서초의 범죄 발생 건수가 다른 구에 비해서 높다.
gu_criminal_norm['범죄'] = gu_criminal_norm['범죄'] / 5
target_col = [ '강간', '강도', '살인', '절도', '폭력', '범죄' ]
gu_criminal_norm_sort = gu_criminal_norm.sort_values(by='범죄', ascending=False)
plt.figure( figsize=(10, 10) )
sns.heatmap( gu_criminal_norm_sort[target_col], annot=True, fmt='f', linewidths=.5 )
plt.title( '범죄비율 (정규화된 발생 건수로 정렬)')
plt.show()
6. 소결 및 시각화 2 - Folium
1) 강남 3구의 범죄 안전도는 높지 않다.
2) 중간 결과 저장
gu_criminal_norm.to_csv('./data_ouput/02.crime_in_Seoul_final.csv', sep=',', encoding='utf-8')
3) Folium
➯ pip install folium
Collecting folium
Downloading folium-0.5.0.tar.gz (79kB)
100% |████████████████████████████████| 81kB 537kB/s
Collecting branca (from folium)
Downloading branca-0.2.0-py3-none-any.whl
Requirement already satisfied: jinja2 in /home/learn/.pyenv/versions/3.6.2/envs/Jupyter/lib/python3.6/site-packages (from folium)
Requirement already satisfied: requests in /home/learn/.pyenv/versions/3.6.2/envs/Jupyter/lib/python3.6/site-packages (from folium)
Requirement already satisfied: six in /home/learn/.pyenv/versions/3.6.2/envs/Jupyter/lib/python3.6/site-packages (from folium)
Requirement already satisfied: MarkupSafe>=0.23 in /home/learn/.pyenv/versions/3.6.2/envs/Jupyter/lib/python3.6/site-packages (from jinja2->folium)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in /home/learn/.pyenv/versions/3.6.2/envs/Jupyter/lib/python3.6/site-packages (from requests->folium)
Requirement already satisfied: certifi>=2017.4.17 in /home/learn/.pyenv/versions/3.6.2/envs/Jupyter/lib/python3.6/site-packages (from requests->folium)
Requirement already satisfied: urllib3<1.23,>=1.21.1 in /home/learn/.pyenv/versions/3.6.2/envs/Jupyter/lib/python3.6/site-packages (from requests->folium)
Requirement already satisfied: idna<2.7,>=2.5 in /home/learn/.pyenv/versions/3.6.2/envs/Jupyter/lib/python3.6/site-packages (from requests->folium)
Installing collected packages: branca, folium
Running setup.py install for folium ... done
Successfully installed branca-0.2.0 folium-0.5.0
import folium
import json
# 행정구역 경계정보
geo_path = './data_science/02. skorea_municipalities_geo_simple.json'
geo_str = json.load( open(geo_path, encoding='utf-8' ) )
4) 서울시 자치구별 살인 사건 발생 상황
# 행정구역도
fmap = folium.Map( location=[37.5502, 126.982 ], zoom_start=11, tiles='Stamen Toner' )
fmap.choropleth(
geo_data = geo_str,
data = gu_criminal_norm['살인'],
columns = [ gu_criminal_norm.index, gu_criminal_norm['살인'] ],
fill_color = 'PuRd',
key_on = 'feature.id'
)
fmap
5) 서울시 자치구별 범죄 사건 발생 상황
fmap.choropleth(
geo_data = geo_str,
data = gu_criminal_norm['범죄'],
columns = [ gu_criminal_norm.index, gu_criminal_norm['범죄'] ],
fill_color = 'PuRd',
key_on = 'feature.id'
)
fmap
6) 서울시 자치구별 인구대비 전체 범죄 발생 비율
tmp_criminal = gu_criminal_norm['범죄']/gu_criminal_norm['인구수'] * 1000000
fmap.choropleth(
geo_data = geo_str,
data = tmp_criminal,
columns = [ gu_criminal_norm.index, tmp_criminal ],
fill_color = 'YlGnBu',
key_on = 'feature.id'
)
fmap
7) 범죄 발생과 검거율을 한 화면에 표기하기
(1) 검거 = 각 항목별 검거율의 정규화 값의 합
gu_criminal_raw['lat'] = station_lat
gu_criminal_raw['lng'] = station_lng
tmp = gu_criminal_raw[ [ '살인 검거', '강도 검거', '강간 검거', '절도 검거', '폭력 검거'] ] / \
gu_criminal_raw[ [ '살인 검거', '강도 검거', '강간 검거', '절도 검거', '폭력 검거'] ].max()
gu_criminal_raw['검거'] = np.sum(tmp, axis=1)
gu_criminal_raw.head()
| 관서명 | 살인 발생 | 살인 검거 | 강도 발생 | 강도 검거 | 강간 발생 | 강간 검거 | 절도 발생 | 절도 검거 | 폭력 발생 | 폭력 검거 | 구별 | lat | lng | 검거 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 중부서 | 2 | 2 | 3 | 2 | 105 | 65 | 1395 | 477 | 1355 | 1170 | 중구 | 37.563646 | 126.989580 | 1.275416 |
| 1 | 종로서 | 3 | 3 | 6 | 5 | 115 | 98 | 1070 | 413 | 1278 | 1070 | 종로구 | 37.575558 | 126.984867 | 1.523847 |
| 2 | 남대문서 | 1 | 0 | 6 | 4 | 65 | 46 | 1153 | 382 | 869 | 794 | 중구 | 37.554758 | 126.973498 | 0.907372 |
| 3 | 서대문서 | 2 | 2 | 5 | 4 | 154 | 124 | 1812 | 738 | 2056 | 1711 | 서대문구 | 37.564785 | 126.966776 | 1.978299 |
| 4 | 혜화서 | 3 | 2 | 5 | 4 | 96 | 63 | 1114 | 424 | 1015 | 861 | 종로구 | 37.571840 | 126.998856 | 1.198382 |
- 경찰서 별 검거 점수에 비례해서 원을 크게 그리도록 함
fmap = folium.Map( location=[37.5502, 126.982 ], zoom_start=11 )
for n in gu_criminal_raw.index:
folium.CircleMarker(
[ gu_criminal_raw['lat'][n], gu_criminal_raw['lng'][n] ],
radius=gu_criminal_raw['검거'][n] * 10,
color='#3186cc',
fill_color='#3186cc'
).add_to(fmap)
fmap
fmap = folium.Map( location=[37.5502, 126.982 ], zoom_start=11 )
fmap.choropleth(
geo_data = geo_str,
data = gu_criminal_norm['범죄'],
columns = [ gu_criminal_norm.index, gu_criminal_norm['범죄'] ],
fill_color = 'PuRd',
key_on = 'feature.id'
)
for n in gu_criminal_raw.index:
folium.CircleMarker(
[ gu_criminal_raw['lat'][n], gu_criminal_raw['lng'][n] ],
radius=gu_criminal_raw['검거'][n] * 10,
color='#3186cc',
fill_color='#3186cc'
).add_to(fmap)
fmap
8) 소결
- 강남3구는 범죄 발생 정도에서 안전하지 않음
- 위 구의 경찰서의 검거 실적이 높지 않음